
はじめに
bitbankでは、主にエンジニアを中心にCursorの導入を進めていますが、希望者に対しては部署を問わずアカウントを発行し、全社的な活用を推進しています。
かなり意外だったのですが、導入直後から非エンジニアのメンバーからのアカウント発行希望が想定以上に多く、半数程度が非エンジニアのアカウントとなっています。
そこで、社内で非エンジニア向けのCursorオンボーディング勉強会を行い、好評でしたので今回公開します。
本資料では非エンジニアがCursorを「活用し始める」ために必要な内容をまとめています。
Cursor、ひいてはAIエージェント一般は、活用できれば業務効率化・自動化に非常に効果的な力を発揮する強力なツールです。しかし、機能が多かったり考え方を変える必要があるため、初めの設定や活用イメージを掴むのが難しい面もあります。
また業界全体の進歩が早いため、ともすれば日々アップデートされるツールや機能に圧倒されてしまい、そのキャッチアップでいっぱいいっぱいになりがちですが、応用のためには基礎的な概念についてしっかり学んでおくことが重要と考えています。
そこで、LLMの基礎知識からCursorの初期設定、レポート作成のハンズオンを通してCursor利用をスタートダッシュするのがこの資料の目的です。
活用開始のハードルを下げることも目的のひとつです。そのため、網羅的な内容ではありませんのでご留意ください。
また Cursorの設定内容や機能についてはあくまでオンボーディング実施時(2026年3月ごろ)のスナップショットであり、アップデートによって現在は変更されている可能性があります。最新の内容はCursorのドキュメントをご確認ください。
モチベーションとマインドセット
なぜCursorを使うのか?
CursorはAIエージェントを使っておもにローカル環境のコーディングなどの作業を自動化するエディタです。ChatGPTやNotebookLMなどとはその点は異なります。
同様の機能を持つツールにCodex、Claude Code 、Copilot、Cline... など沢山の選択肢があります。
なぜCursorを選ばなければいけないのか、もしくは主流のツールが決まってから学んだほうが良いのではないかと二の足を踏んでいる人もいるかもしれません。
結論から書くと、実はとくにCursorでなければいけない理由はありません。
「AIに作業を任せる」ことができるツールであり、学べるマインドセットやノウハウが同じならどれでもOKと考えています。
マインドセット
まとめてしまうとわたしたちが持つ必要があるマインドセットは以下だけです。
AIに作業の主導権を握らせて人間はAIのサポート(指示・確認)を行う

たとえば仕事についての質問をして回答をもらうような使い方は、あくまで主導権が人間にあり、補助的な使用方法といえます。それだけでも十分便利ですが、AIエージェントは「任せる」使い方をしないと本当の効果は出ません。
一方で、任せた結果、人間になにもやることがなくなるということは(残念ながら)ありません、AIにどんな情報を渡せばいいか、どうフォローすれば意図通りの成果物ができるかを考えていく必要があります。
このとき、渡す情報の選び方、効果的な指示の仕方、段取り、AI・LLMの得意・苦手な作業。これらの考え方やノウハウはどのツールでも共通であり学んでも無駄になりません。
ツールによる違い
ツールによる違いももちろん存在します。
- サポートの仕方、UI(GUI/CLIレベルで違う)・画面の使い勝手、デフォルト機能
- 利用できるモデルの種類。モデルプロバイダが提供するエージェントはモデル縛りがある場合が多いです(一方でモデルに最適なツール・機能を早く出せるという面もあります)
競争が激しいため、利用できる新機能の差分はそれなりにメジャーなサービスであればすぐに追随される状況にあり、あまり機能でえり好みする必要がないと考えています。すでにコモディティ化が進んでいる状況ではないでしょうか。
例: MCP、スキル、サブエージェント
付録:エディタ(IDE)とは?
- メモ帳のようにMacのストレージに保存したファイルを編集することができるのがエディタです。
- ざっくりIDEはエディタの高機能版です。
▷エディタとIDEについて
Mac上のフォルダを開くことができる。
Cursorの例だとフォルダを開くと左のサイドメニューにフォルダが展開される。
選択したファイルを切り替えて編集できる
- 開いたフォルダとその中のファイルをひとまとまりとして「プロジェクト」と呼び、その単位で設定などを扱うことができる。
- 編集が必要なたくさんのファイルを同時に扱うときに便利な機能が盛り込まれている。
例:検索機能はプロジェクト内のファイルを全部高速に検索できる
AIに対して持っておいてほしいマインドセット
メンタルモデル以外で前提として知っておいてほしいことをまとめました。
確率的である
AIの応答がいくら人間っぽく見えたとしても、基本としては文章の続きを推測して補完している『だけ』です(「LLMは本質的に、トレーニング中に提供されるテキストを模倣するテキスト補完エンジンにすぎない」LLMのプロンプトエンジニアリング)。
またLLMのレスポンスは、プロンプトと学習データから生成されますが、AIエージェントの場合は意図的にランダム性を含ませられており、より確率的です。
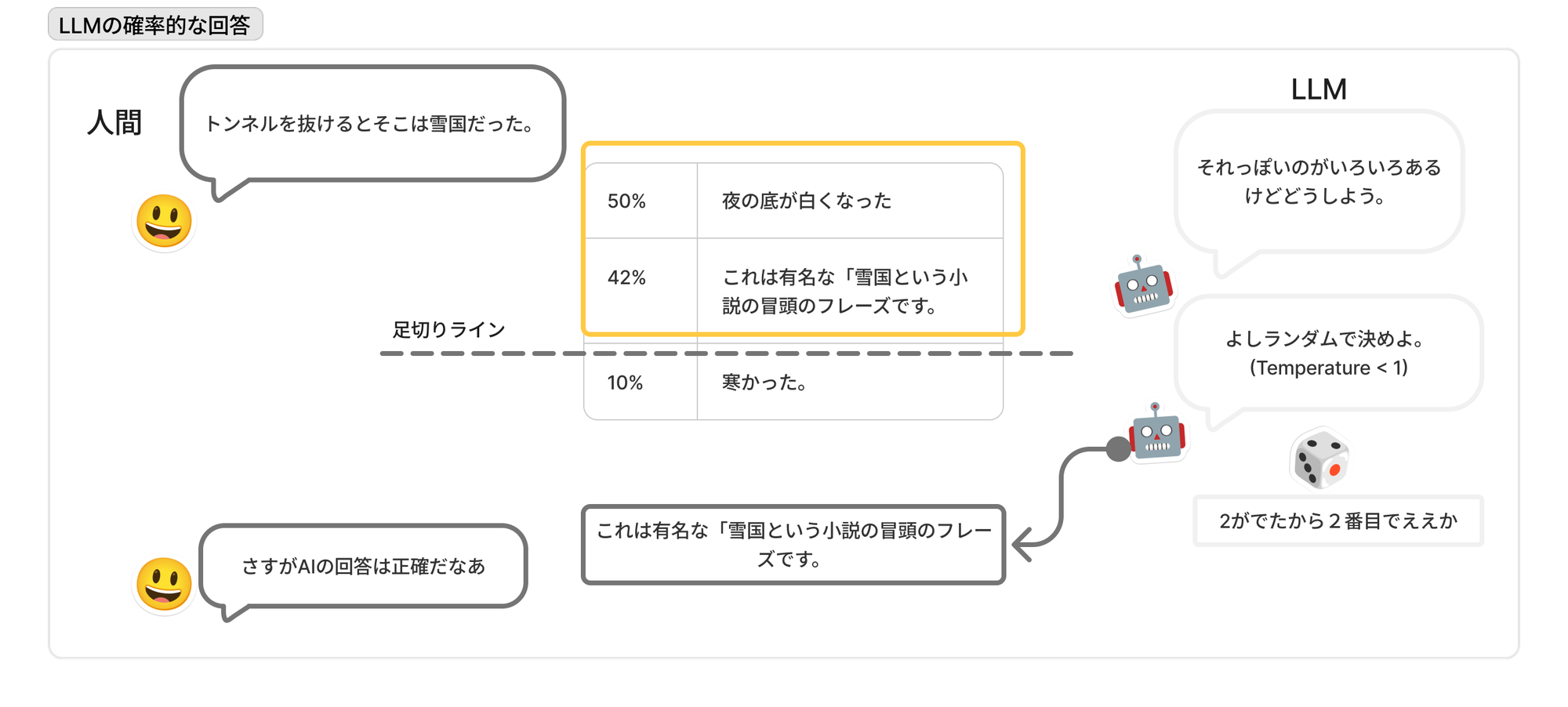
※エージェントは確率的にしないと無限ループに入ってしまう危険があり決定論的な設定にできません。
苦手分野が存在する
人間に苦手分野があるのと同じく AIエージェントには苦手分野があります。
「AIとやり取りしていて何度訂正しても同じ間違いを繰り返す」という話を聞くことがありますが、これは前述の「文章の続きを推測して補完する」という原理を知っていれば当然であるのがわかると思います。何度も間違えるやり取りの続きの文章は、また間違える文章である可能性が高いためです。
世間には今のAIの苦手分野を学んでもモデルが改良されて克服されるから無駄だという人も結構いますが、このように「原理的」に苦手な分野というのは近い将来に改善する見込みは低いためAIを活用するためには学ぶ価値があります。(AGIが出てきたときのことはその時にまた考えましょう)
全部は挙げられませんが、いくつかの苦手分野の例をあげてみます。
- もともとの人間の指示やそれまでのやりとりが「間違っている」場合の軌道修正
- コンテキストとトレーニング内容に含まれて「いない」内容すべて
- 文字数カウントなどの数理計算
ここで苦手な理由の深堀りはしませんが、苦手分野があることを理解すればうまい使い方がわかります
- 「軌道修正が苦手」→「方針転換が必要なときはセッション(会話)を打ち切って、正しい方向に誘導しつつ新しく会話を始める」
- 「知らない情報を捏造してくる」→「信頼できる参考情報をダウンロードして
/docsフォルダに置いて読ませてから回答させる」 - 「数理計算が苦手」→「スクリプト(小さなプログラム)を組んで計算するように指示する」
他にも、「藁束の中の針問題」「ピンクの象問題」「無関心の谷」「赤ずきん原則」など面白い名前の苦手分野や特性が存在するので気になる人は調べてみてください。
AIの苦手分野を理解して人間が対応する工夫が普遍的なAIエージェントのベストプラクティスになりつつあります。
責任
成果物の最終責任は相変わらず人間にあります。AIエージェントが書いた内容は完成形ではなく、自分の基準を満たしていることを精査して初めて完成となると考えましょう。
AIエージェントの基本知識
モデル
使うAIの種類です。
AIなんてどれも同じだと思われるかもしれませんが、それぞれ特徴があります。
比較ポイントはスピードと品質、次点で価格。最後に機能(マルチモーダルやコンテキストの長さ)です。
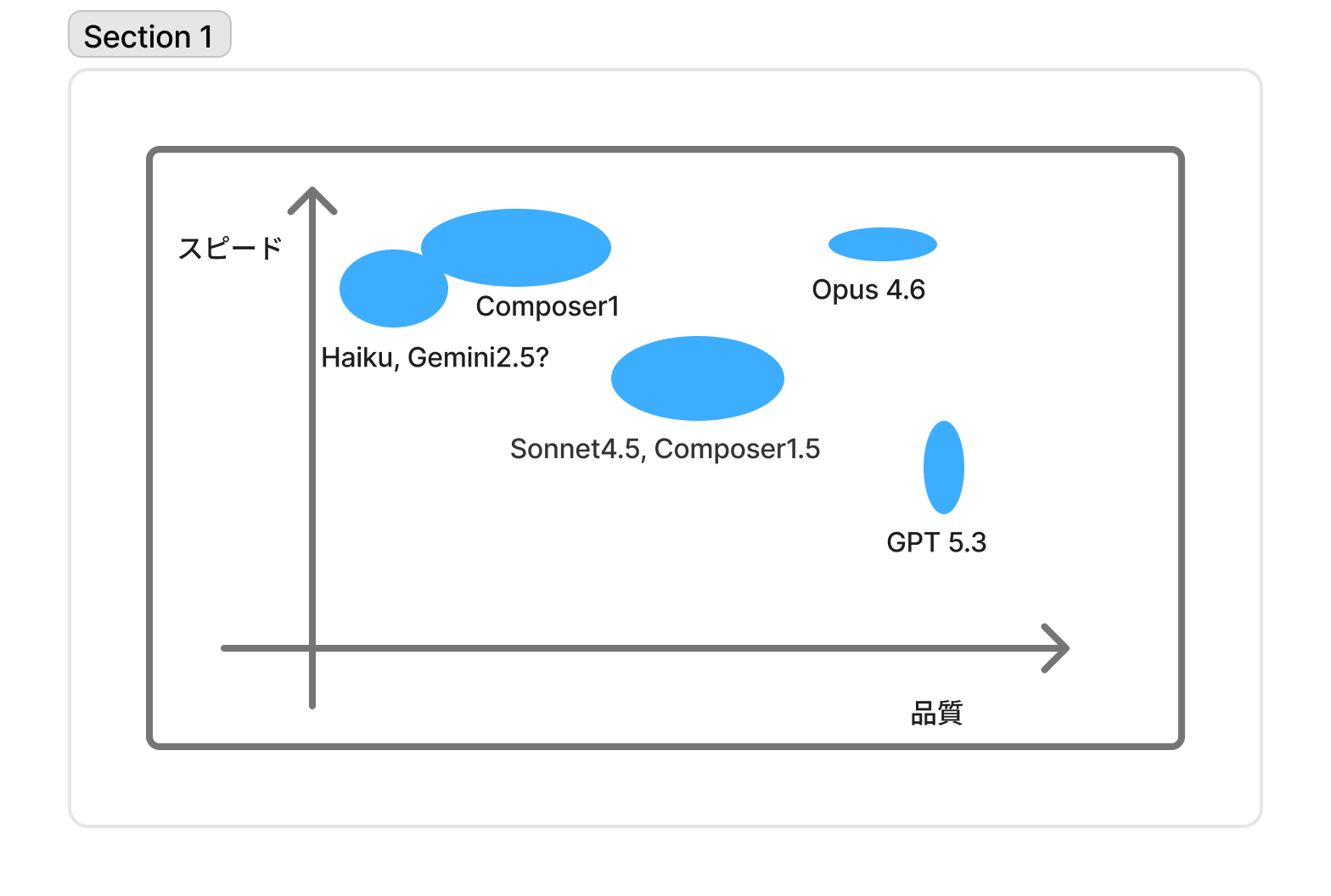
※上記は2026年3月時点の作者の個人的な経験と独断と偏見によるモデルマッピングなので参考程度にしてください。
選び方
基本的な考え方としては、お金の縛りがないならSOTA(State of The Art: 現在最強)モデルを基準として使い、「この作業なら弱いモデルでやったほうが早い(やすい)な」と思うときに弱いモデルを選択して使い分けるべきです。
その理由は以下の2つです。
- モデルの進化のスピードが早いため弱いモデルでなんとかするノウハウを学んでも将来新しいやすいモデルで解決して無駄になる可能性が高い
- SOTAモデルはモデルの進化の方向性を示している可能性が高く人間側の学習の無駄が少ない
ただしCursorの利用について絞ると以下を抑えておいてほしいです。
- CursorのAutoはタスクに対してちょうどいい品質ではなく低品質モデルである(2026年3月現在)
ただしSOTAモデルはお金がかかりすぎて一瞬でクレジットを使い切るような場合もあり、デフォルトで活用するのは非推奨としたほうが良い場合もありえます。組織の予算やプランによって使い分けましょう。

引用元: 呪術廻戦/芥見下々/集英社
コンテキスト
エージェントのモデルに実際に渡されるデータには直接のユーザープロンプト(チャットに入れる文章)以外にも「コンテキスト」データがあります。
実は割合としてはプロンプト以外のコンテキストデータがほとんどです。
ユーザー指示以外のコンテキストとは
ユーザー指示以外にもAIエージェントのモデルに渡したいデータはたくさんあります。
これらのデータはCursorのUI上からは人間には直接は見えなくなっていますが、集約されてLLMのモデルに対して渡されています。
コンテキストの例
- システムプロンプト
- ユーザー作成のカスタム指示(ルール)
- ツールの情報
- 読み取ったファイルの情報
- 各種履歴
- etc..
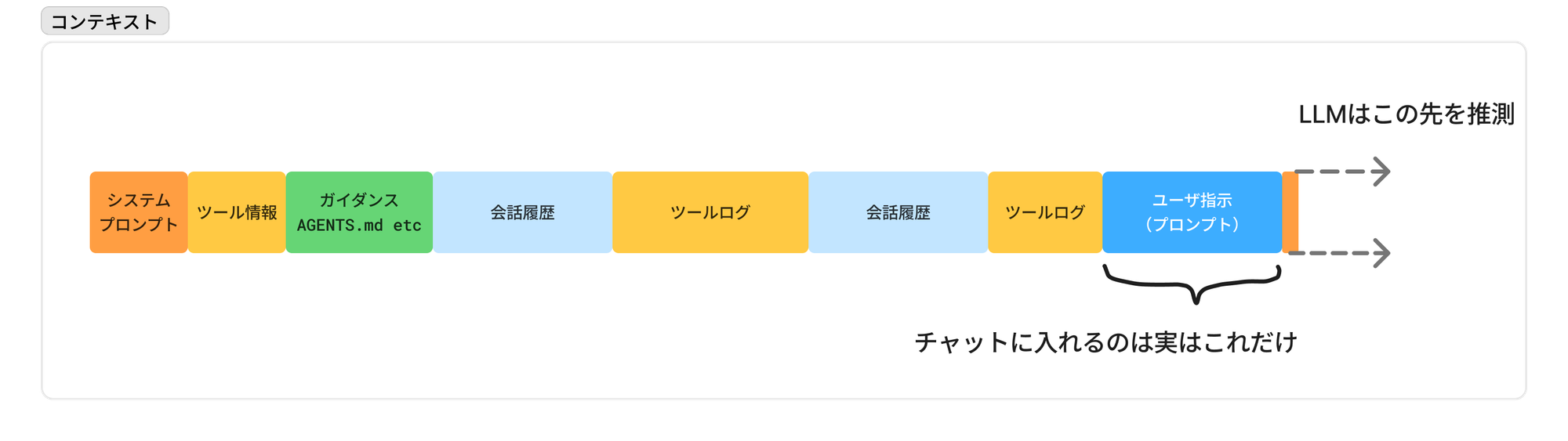
コンテキストのイメージ
セッションの繰り返しでコンテキストが増大する
過去のセッションの履歴は次の会話のコンテキストに積み上がって追加されていきます(図参照)。そのためやり取りを繰り返せば繰り返すほどコンテキストが長くなっていきます。
また、ツールの実行ログなど多いコーディング作業では特に大量のコンテキストが追加されます。
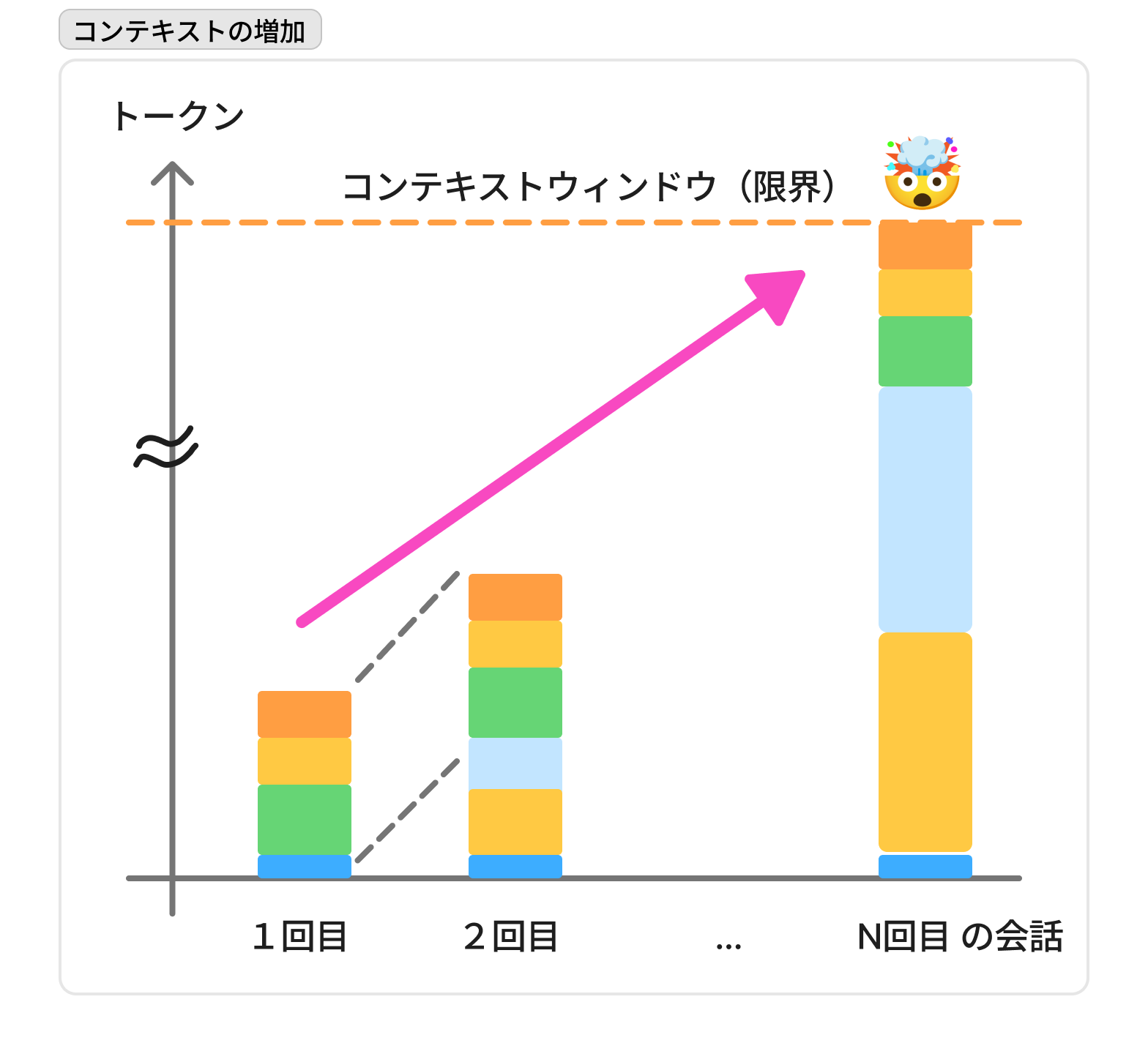
コンテキスト管理の重要性
コンテキストについての基本的な考え方として「長いとだめだが無いともっとだめ」ということを覚えておいてください。
AIのモデルが一度にわたせる情報量には上限があり、それを「コンテキストウィンドウ」と呼びます。また、過去履歴を積み上げていることからもわかると思いますが、AIのモデル自体には記憶がないため、モデルは会話ごとにゼロからコンテキストを全部読みなおして続きを推測しています。
コンテキストが長い場合一般的に以下の問題があります。
- コンテキストが増えると応答速度が遅くなる(
応答時間=トークン数 x モデルの処理速度のため) - コンテキストウィンドウ内であっても、情報が多いと内容が埋もれ、品質が落ちる。(藁束の中の針/Needle in the Hay効果)
一方でコンテキストに必要な情報がないと以下の問題があります。
- コンテキストにないことは知らないのでできない
- コンテキストウィンドウがあふれると、古い情報は捨てられてしまうか圧縮される。はじめにした指示などが失われるため、AIが指示を忘却してしまうような品質劣化が起きる。
つまりコンテキストの長さには明確にトレードオフがあります。必要な情報を含めつつコンテキストが長くならないようにする、コンテキスト管理が重要になります(コンテキストエンジニアリングのような呼びかたもします)。
AIエージェントに渡す情報はタスクに関係ない情報を含めないようにして必要な情報のみにしぼることが重要です。
やり取りが長くなってきたら、必要な情報をまとめて新しい会話(セッション)を始めることが基本のベストプラクティスとされています。
そうはいっても長くなったセッションの内容を引き継ぎたい場合もありますが、コンテキストが溢れる前に引き継ぎドキュメントとしてまとめさせて次のセッションのために残しておくのが良いでしょう。
ツール
AIのできること。手足です。
AIエージェントは一般的に以下のようなツールを使用できます。
- ファイルの読み書き検索
- コマンドラインツール(CLI)
- 非エンジニアであれば馴染みがないと思いますがMac・PC上でできることが基本的に全部できると考えてください。
- Macでデフォルトで入っているのは
zsh。Homebrewとかを入れればもっとなんでもできますが、リスクもあるので理解できないくらい複雑なことはやめましょう。
- MCP
- ツールを標準化したものです
ルール
「こんなやり方でやって」といった作業指示をあらかじめ設定しておける。AIの動きをコントロールするために、毎セッションでAIに持っていてほしい前提知識を植え付けられるのがルールです。
「ルール」「カスタムインストラクション」「AGENTS.md」「CLAUDE.md(Claude Codeの場合)」のような呼ばれかたをしますが基本的に同じものだと思って大丈夫です。
仕組みは単純で、ルールに書いた内容をモデルに渡すコンテキストに必ず含めるようになっています。ルールを活用することで、以下の利点があるといわれています。
- ルールに毎回前提として知っておいてほしいことを書いておくことで、毎回の会話でプロンプトとして書く必要がなくなる。
- 業務のドメイン知識を渡しておいてドキュメントとして育てていくことで、低コンテキストでより出力の品質を上げることができる。
- 以前の会話での失敗をフィードバックすることでエージェントが同じ失敗をすることを防止できる
仕組み上コンテキストを消費するため、最小限から始めて、毎回プロンプトに必要になること、毎回エージェントが失敗することを追加していくのがベストプラクティスとされています。
例:
# AGENTS.md
## 基本方針
- 私は非エンジニアです
- あなたは業務をサポートするエージェントです
- 指示の情報が足りないときは2回質問してください
## このプロジェクトについて
bitbankの社長の業務自動化を目的としたプロジェクトです。
## 回答品質
- 絵文字を回答に入れない
- 複雑なスクリプトで問題を解決しない
- タスクが完了したら `say "完了しました"`を実行しなさい
スキル
スキルは繰り返し行う作業の「情報・作業手順」をまとめたものです。
一度作っておけば、ある程度あいまいに日本語で指示しても同じ手順で毎回やってくれる指示書・手順書のようなものと考えてください。
情報の段階的開示によりコンテキストの増大を抑えつつ正確な手順の指示ができることと、Cursorを使っておこなった作業をすぐに自動化できるのが強みです。これは割と新しい機能ですが恩恵がわかりやすいのと、ハンズオンに使用するため紹介しました。
参考: https://agentskills.io/home
インストールと基本設定
ここからハンズオンです。実際に手を動かして使い方を学びましょう。
Cursorのインストール
公式サイトからダウンロードしてインストールします。
基本設定
初期設定を行います。
CursorSettingsの場所は?
そもそもCursorは設定が多すぎて慣れないと目的の画面にたどり着くのが難しいです。以下の方法でCursorの設定を開くことができます。
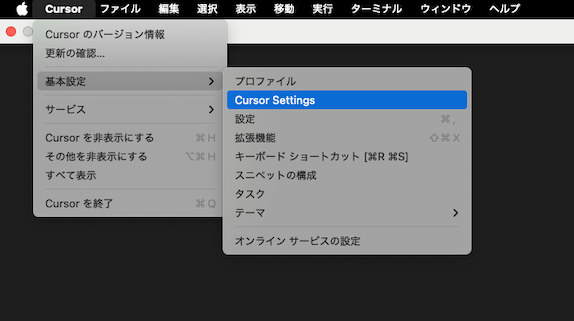
- メニューバーのCursor > 基本設定 > Cursor Settings でCursorの設定にたどり着けます。
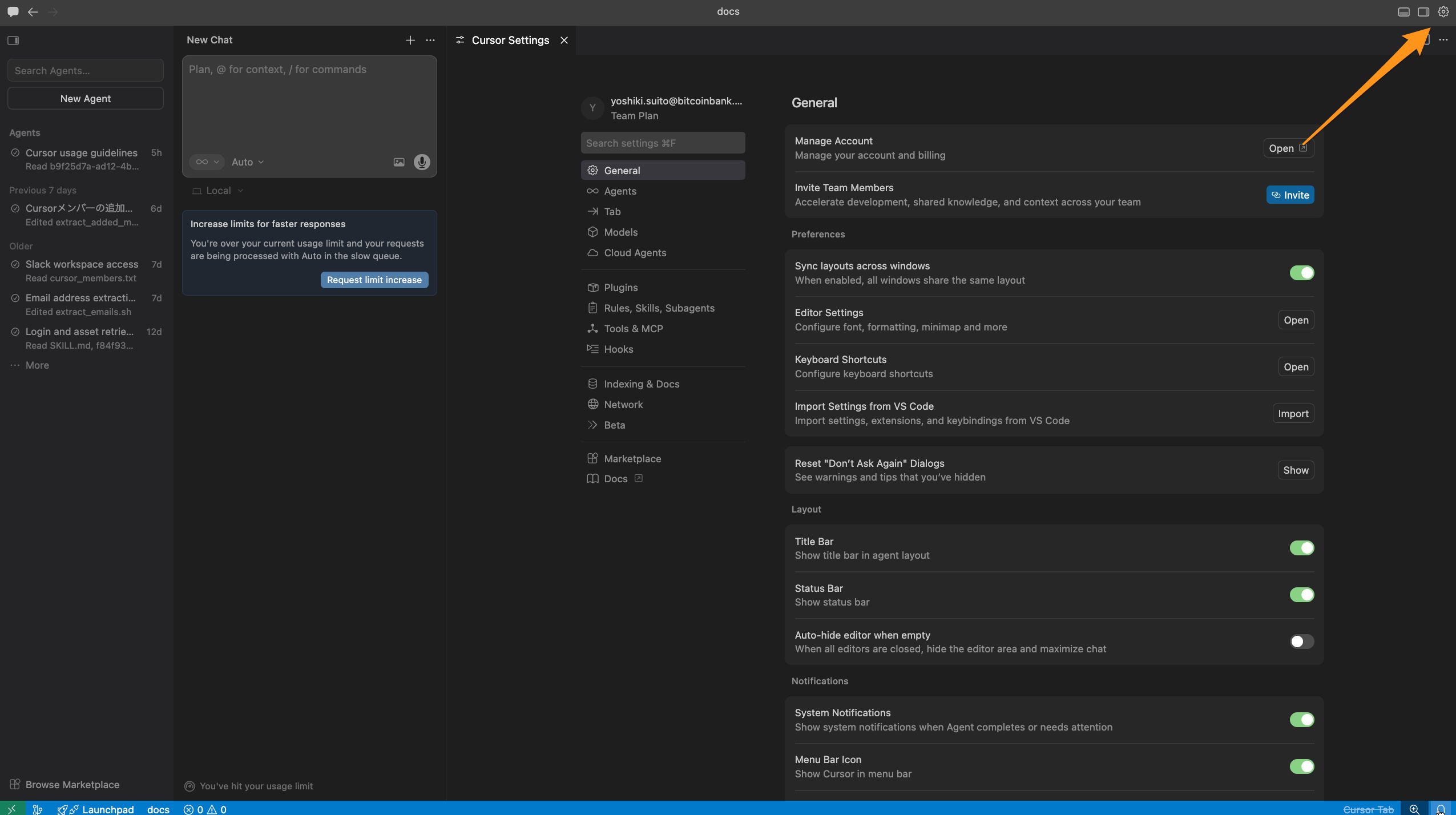
- 右上の⚙️アイコンから、SettingsをクリックしてもCursor Settingsを開くことができます。
Agents
Agents モードを活用するとエージェントにファイルの編集やコマンドの実行などの権限を渡し自律的に実行させることができます。一方で不要な設定や設定の解除の状態によってはリスクが高まるため必要最小限の権限で最大限活用できるように推奨設定を社内で共有しています。
※機能開発のスピードが早いためあくまで現在(2026年3月)のスナップショットであることにご注意ください。アップデートによって設定内容や選べるモードが変更になる可能性があります。
- Auto-Run Mode
Auto-Run in Sandbox
- Auto-Run Network Access
sandbox.json + Defaults
- Command Allowlist
- 取り返しがつかない場合がある強力なコマンドの登録は非推奨 (
rmなど) - 実質何でもできるコマンドは設定しない (
node,python,bashなど) - 登録しなくても実行時に確認が入るだけで実行できなくなるわけではないのであらかじめ洗い出して網羅的にコマンドを登録する必要はない(必要になったときに追加すればよい)
- 取り返しがつかない場合がある強力なコマンドの登録は非推奨 (
- MCP Allowlist
- bitbankではリスク評価が完了したもののみ設定するようにしています
- Browser Protection
- 有効化
- File-Deletion Protection
- 有効化
- Dotfile Protection
- 有効化
- External-File Protection
- 有効化
日本語化の方法
非エンジニアへのオンボーディングを実際にやってみてわかったのですが、日本語化が鬼門でしたので解説しておきます。
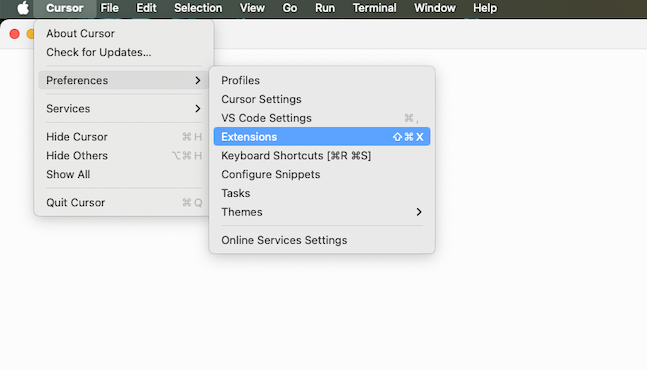
- メニューバーから
PreferencesのExtensionsを選択します
- Cursorのサイドメニューに
ExtensionsがでるのでJapaneseで検索
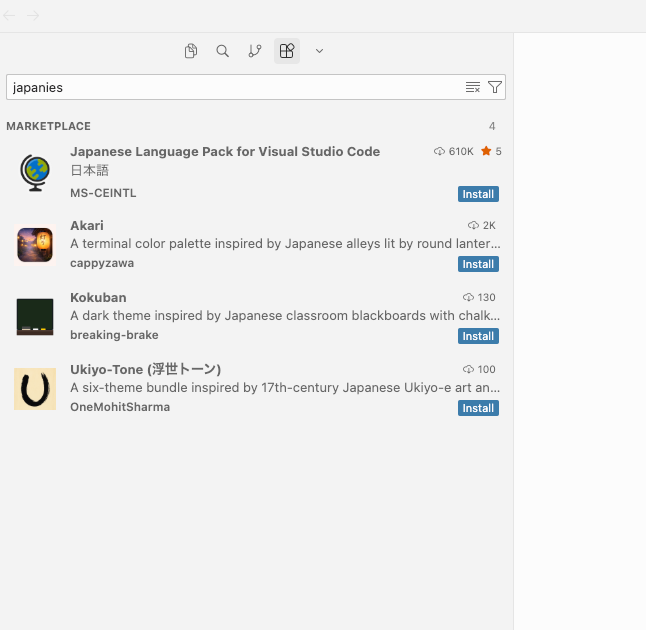
Japanese Language Pack for VS Codeを選んでインストールしてください
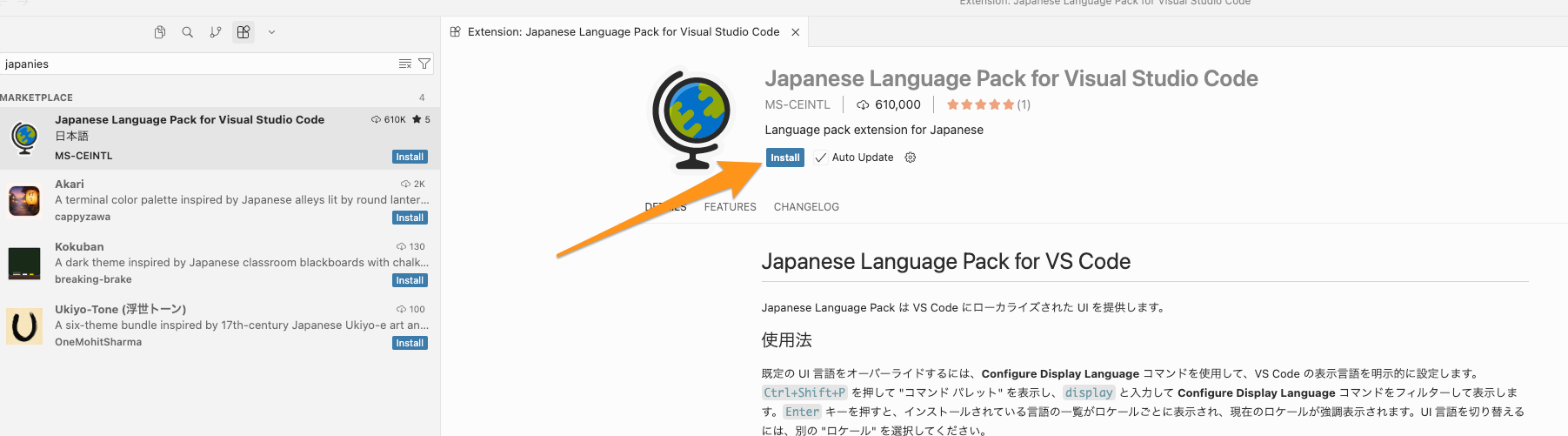
- 左下に小さなダイアログが出てくるのでボタンをクリックしてCursorの言語を変更してリスタートする
- メニューの項目が日本語になっていたら成功
その他
- Tools&MCPのBrowser Automationは
Browser Tabにしておきましょう。 - Protection系の項目は基本ONが良いですが、
Browser ProtectionをONにしておくとブラウザ操作に毎回許可が必要になってしまうので自社ページなど安全であることがわかっているページを開く場合はOFFにしましょう。
定型作業の自動化ハンズオン
実際に定型作業を自動化する手順を体験します。ルールやスキル、ツールを活用して、繰り返し行う作業を効率化しましょう。
廣末さん朝会レポート自動化スキルの作成
bitbankの代表取締役の廣末は毎日オンラインミーティングで全社員に向けて朝会を行っており、世界情勢から経済ニュース・業界の最新情報を短い時間で紹介しています。
社員は毎日それを聞いてから仕事に取りかかるのが日課となっています。
今回は、この朝会のニュースのレポートの生成をテーマにハンズオンを行っていきます。実践を通じて、スキルの作成方法と活用のコツを学びます。
※プロンプトに例示したものが実際のレポートです
最初のプロンプト
プロジェクトを作成して、最初のプロンプトを実行していきます。
- フォルダを適当な名前で作成してそのフォルダでCursorから開く
- AGENTS.mdという名前のファイルを作成し先程の例を記載
- PlanモードでモデルをComposer2等に変更し以下のプロンプトを入力して実行します
▷プロンプト
私はbitbankの社長です。毎朝社員に以下のような内容で業界のニュースを共有しています。今日の分をまとめてください!
"""
2026/2/12
■政治経済
米雇用者数は予想上回る伸び、失業率4.3%に低下-労働市場の改善映す
https://www.bloomberg.com/jp/news/articles/2026-02-11/TAAR1NKJH6V900
米資産の削減、世界の機関投資家4割が計画 世界でじわり進む「米国売り」
https://www.nikkei.com/article/DGXZQOGN03C670T00C26A2000000/
金融庁肝いり「金融版アマゾン」不発 保険仲介増えず、制度見直しへ
https://www.nikkei.com/article/DGXZQOUB1418W0U5A211C2000000/
今週の主な経済・投資関連イベント
https://x.com/sikeda23/status/2020163422189506845/photo/1
■株価
NYダウ、反落し66ドル安 利下げ観測の後退が重荷
https://www.nikkei.com/article/DGXZQOFL120500S6A210C2000000/
日経平均 休場
■クリプト
Bitcoin ETF Flow (US$m) +140m
https://farside.co.uk/btc/
Crypto Fear & Greed Index Over Time 11 Extreme Fear
https://alternative.me/crypto/fear-and-greed-index/
半値のビットコイン、量子コンピューター解読力が脅威に
https://www.nikkei.com/article/DGXZQOGN113YM0R10C26A2000000/
銀行側が初めて例外措置に言及、米ステーブルコイン利回り協議で
https://coinpost.jp/?p=688450
米CME出資のブロックフィルズ、仮想通貨入出金を一時停止 市場急落受け
https://coinpost.jp/?p=688452
野村系、26年に暗号資産交換業を申請へ 大和証券・日興証券も検討
https://www.nikkei.com/article/DGXZQOUB056P00V00C26A2000000/
「暗号資産交換業等におけるサイバーセキュリティ強化に向けた取組方針(案)」
https://www.fsa.go.jp/news/r7/sonota/20260210-2/20260210-2.html
・サイバーセキュリティセルフアセスメント(CSSA)を暗号資産交換業者全社に実施することを求める
・サイバーセキュリティに係る人的構成について、必要とされる専門性、適切な人員配置、サイバーセキュリティ責任者の権限に係る基準の在り方を検討する
・外部監査について、システムリスク管理、署名鍵管理等を対象とする外部検証の在り方の明確化を検討する
・外部委託先に求めるべきサイバーセキュリティ要件についても、実務上の課題と最新の技術動向を踏まえた包括的な再検討を行う
・各事業者による JPCrypto-ISACなど情報共有機関 への積極的な参加を促す
・Delta Wall、暗号資産交換業者には定期的な演習への参加を引き続き求め、3年以内に全社の参加を目指す
・2026 年中に、全事業者のうち数組織に対して、 実運用環境への TLPT を実施する
"""
壁打ち
- Planモードで質問が来れば回答を行います
- プランのドキュメントが完成したら、それを読んでフィードバックをしてください
- 例
- 「Slack配信は自動化しなくていいです。レポートをマークダウンにまとめてくれればコピペは自分でやります。」
- 「私は非エンジニアなのでスクリプトは最小限にして自然言語のワークフロー手順書をAIエージェントに読ませて作業させるようにしたいです。pythonは厳しいです。」
- プランが練り上がったらBuildをおして実行開始
- 成果物の品質を確認して問題があれば修正を指示します
- 今回の作業の場合
Fetchツールの実行許可確認が発生するはずです。確認して、問題ないサイトであればallow listに追加しておきましょう。
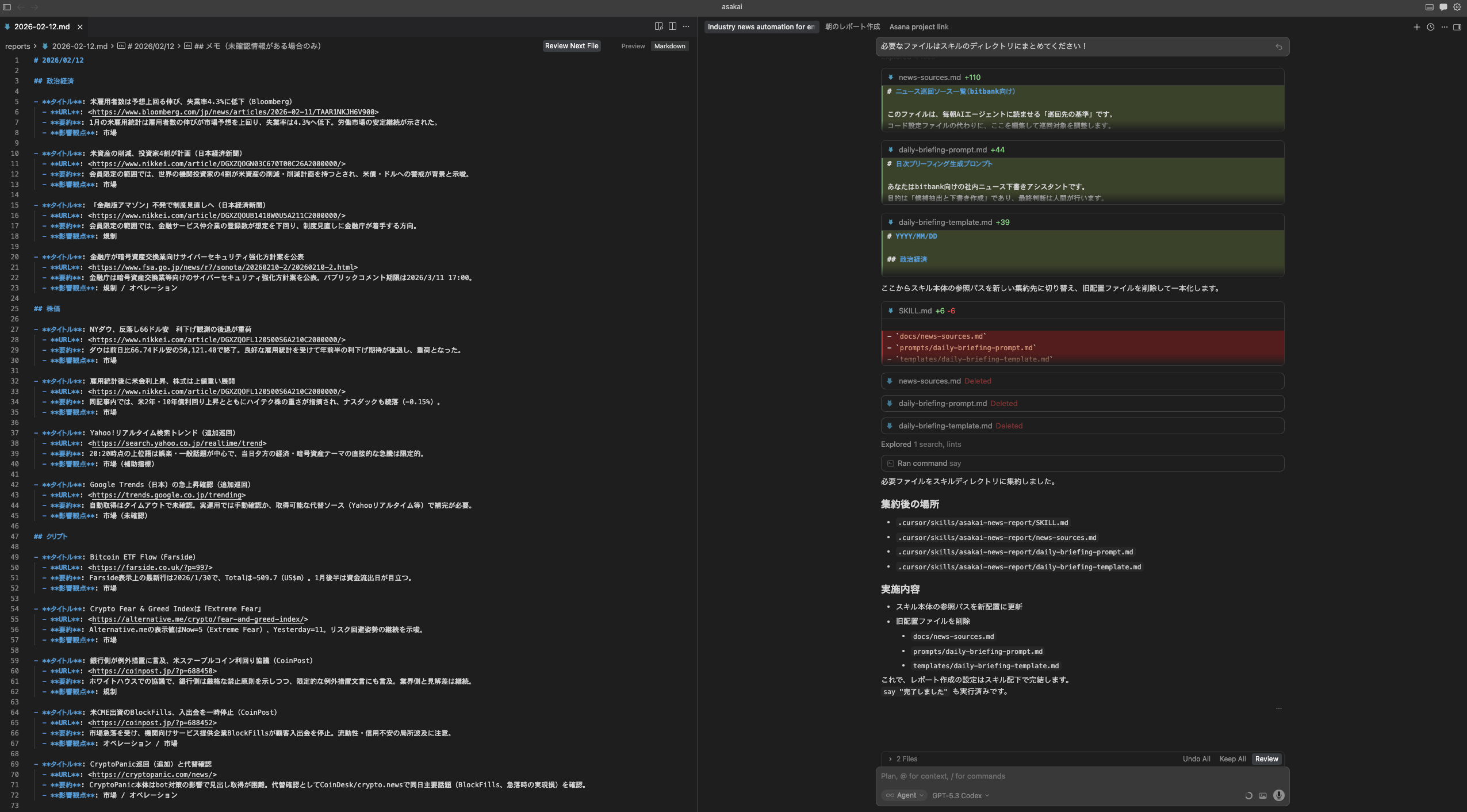
スキル化
- スキル化
- 「今行った作業をスキルにしてください!」もしくは
/create-skillというスラッシュコマンドを使用してスキル化します- 例: 「
/create-skillこのレポート作成作業をスキルにしてください」
- 例: 「
- 適宜追加指示
- 「スキルに必要なファイルは全部スキルのフォルダに入れてほしい」「結果は
asakai-outputというフォルダに出して」など
- 「スキルに必要なファイルは全部スキルのフォルダに入れてほしい」「結果は
- 動作確認
- 別のセッションで「今日の朝会資料作って」「朝会資料くれ」と書く
- スキルを呼出して朝会資料を作ってくれたら成功
- 応用:様々な条件でのテスト
- 雑な指示でもスキルを発動できるか?
- 「朝会やって」「麻会資料よろし」
- 他のモデルでもスキルが実行できるか?
- 早い・安いモデルでも問題なく実行できるか試してみましょう。つまったり失敗した部分はスキルにフィードバックさせましょう。
- フィードバックといっても「詰まった部分をスキルにフィードバックしてください」と指示するだけです。
- 早い・安いモデルでも問題なく実行できるか試してみましょう。つまったり失敗した部分はスキルにフィードバックさせましょう。
以上で初めてのスキルの完成です!ぜひ日々の業務でスキルを活用してください。
FAQ
最後に社内のオンボーディング勉強会で実際にでた疑問質問です。
Q: エンジニアがどうUsageをケチってるかを知りたいです
A:
- セッションを細かく切り替えるようにしたり、モデルの価格を参考にして安いモデルで済みそうなタスクは安いモデルに任せたりしています。
- Codexなども使えるのでクレジット切れたらこちらを利用する場合もあります
Q: ディレクトリはプロジェクト別に作っておいて、中は適当にしちゃっていいですか? AGENTS.mdと作業用ファイルを同じところにおいていいものなのか?
A: 一緒にして問題ないです
Q: .cursor/rulesは作るべきか
A: rulesも自分で使う分には良いんですが、Cursor以外のツールは読み込んでくれない問題があるため、基本的にはAGENTS.mdとスキル(Agent Skills仕様)で実装することを推奨しています。自分は新しく作成する際にはAGENTS.mdを使用するようにしています。*.mdcをつかうのはCursorの独自仕様です。
Q: 作ったスキルを定期実行させることは可能ですか?
A:
- Cloud Agents という機能を使えば可能です
- 他のやり方だと、たとえば毎朝Cursorを立ち上げたときに、「朝のルーティンワークやって」と指示すると展開するスキルを作成してそこに毎日必要な作業をリストにして、他のスキルとして読んで実行させるようなやり方も考えられます
- エンジニアであればMacのcronを設定して Cursor CLI を実行させるなどもできそうですが、非エンジニアでは難しいので非推奨です
Q: Cursorの推奨設定は、例えばClaude Codeなどでも使い回せる?
A: これはあまり使い回せません。似たようなものはあるので(sandboxモードなど)参考にはできるかもしれません。
Q: 資料を読み取らせるのってフォルダ内にファイルを作って「これを読んで」ってすれば良いですか? 社内のドキュメント管理ツールで管理しているドキュメントを読ませたかったらどうすればいいですか?
A: その通りです。テキストのファイルを作ればそのまま読み取ってくれます。また利用しているサービスがMCPに対応していれば、そのMCPを利用することでCursorから直接ファイル読み取らせることもできます。
Q: ルール(AGENTS.md)の共有方法
A:
- プログラマだとリポジトリごとにgitで共有できますが、非エンジニアの場合ちょっと手間だがAGENTS.mdを社内のドキュメント管理ツールなどで共有することは可能です。非エンジニアが業務上やりやすい方法は今後検討していく必要があります。
- チーム全体でチームルールを適用することもできますが、業務がそれぞれ異なる人間に一律に設定することになってしまいまうためかなり横断的なルールに絞る必要があります。
Q: QAで使う信用取引の計算式をスプシで実装しているがスキルでそれを置き換えることはできる?
A: できると思います。ただし、単純にみえる計算でもモデルは苦手な場合があるため、スキルにする場合は「スクリプト化」するように指示して計算させるのがよいです。
Q: 取引所画面の数字をみてそれを読み取って信用取引の維持率を計算させる、ようなことはできる?
A: ブラウザ機能で開発環境や本番環境の取引所にCursorのブラウザツールでアクセスさせることができます。そこで数字を読み取らせることでできると思います。
Q: 画像を読み込めますか
A: 読み込めます。モデル依存があったのですが、いまではほとんどの上位モデルが画像読み取りに対応しているのであまり気にする必要がありません。

