
はじめに
社内文書検索をいい感じにするslackボットをChatGPTのAPIとノーコードツール(Zapier)を使用して作成したので紹介します。
BitbankではDocbaseというマークダウン形式でドキュメントを作成できるナレッジベースのSaaSを使用しています。
弊社ではもともと社内文化として"ドキュメンテーション"が根付いており、作業手順などのマニュアルはもとより議事録や設計書などの技術文章からアイデア出しの資料やポエムまで、沢山のドキュメントが作成されて公開されています。特に弊社はフルリモートワークの会社であるため、あらゆる社内のナレッジをドキュメントとして公開し社員に共有していくことは非常に重要です。
一方でドキュメント数が増えすぎて目的の文章を見つけるのが難しくなっているという課題がありました。
典型的な例を紹介すると、"Familia"というプロジェクトの設計書を探そうとして"Familia 設計資料"という検索文言で見つけようとしても定例の議事録に埋もれて出てこない、というようなことがよくありました。
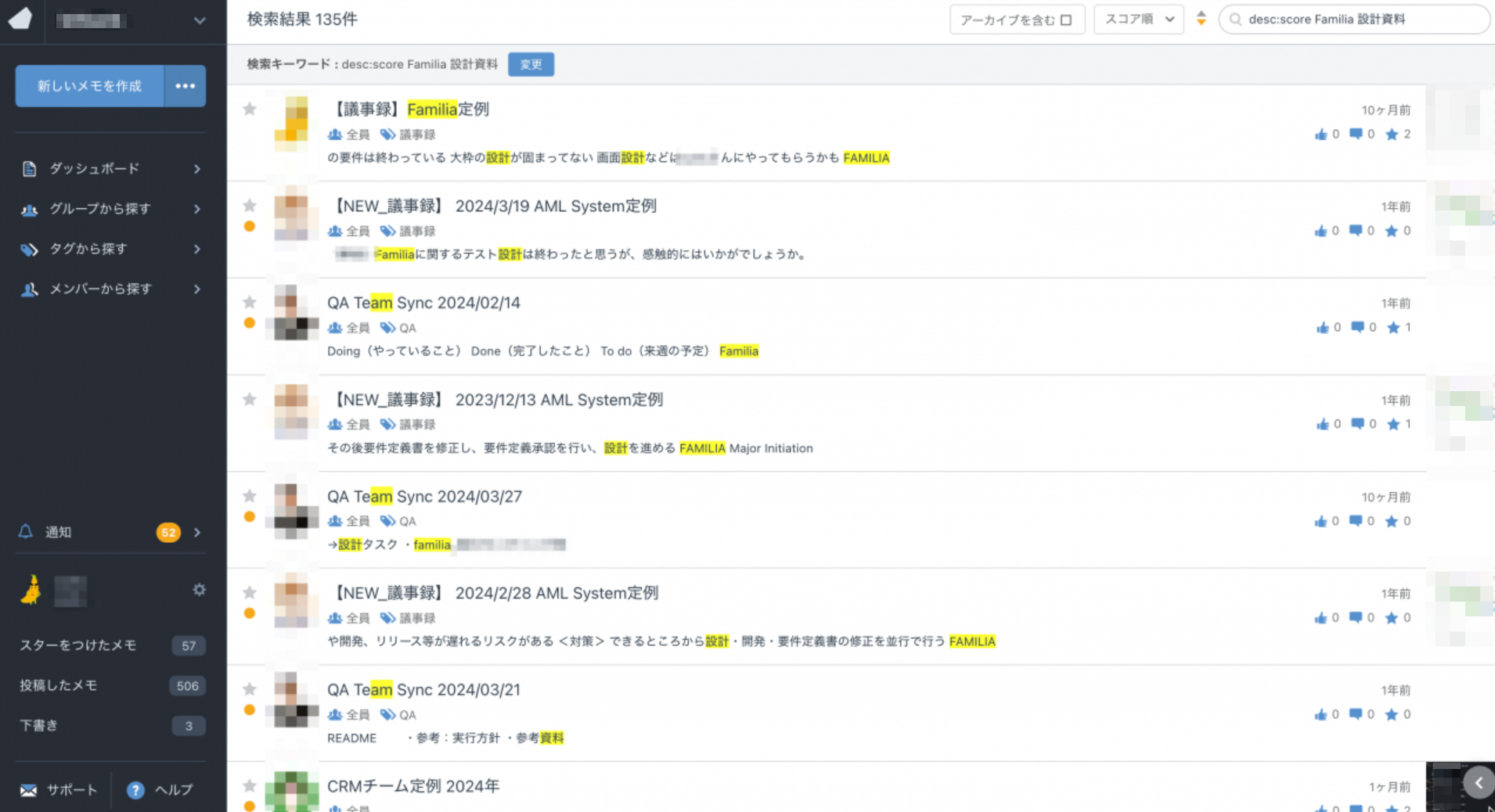
※ちなみに実際にFamiliaというプロジェクトは存在するし設計書も存在します。
Docbaseさんは高度な検索クエリが使用できるためこれらを駆使すれば実は見つけることはできます。(逆にいうと類似検索機能が弱いのかなという気がします)
ただこのナレッジベースは非エンジニアも使用するものであり、検索クエリを学んで慣れるのも大変だし、もっとなにも考えずに目的の資料が出てきてほしいよねという課題感がありました。
この問題を解決するためのslackボットを構築し目的のドキュメントがすぐに見つかるようになりました。
ITエンジニアの方であればChatGPTのAPIを使ってドキュメントを見つけるツールを作ったと聞けば、「RAGを使ったの?」とか、「LangChainを使用したのかな?」とか考える方も多いかと思いますが、実はそういう高度なもの(?)は全く使わずに、ChatGPTのAPI(OpenAI API)と各サービスをノーコード(ローコード)ツールのZapierで呼び出して組み合わせるだけで実現しています。
なぜつくったのか?
このツールを作った動機としては前述の課題解決の他に、ChatGPTや大規模言語モデル(LLM)の技術の個人的なキャッチアップという面もありました。プログラマーとしては新しいものを学ぶにはそれでなにか役に立つものを作ってみるのが一番、とよくいわれると思います。ようするにそれです。
いろいろ社内を巻き込む必要がある本格的なシステム導入などではなく、メンテしやすいノーコード(ローコード)を活用したり簡単に導入できるslackボットという形を取ったりしているのはそういう背景があります。
ChatGPT APIを活用した社内文書検索のハック手法
今回のブログで紹介するハック手法の概要は下の図のとおりです。
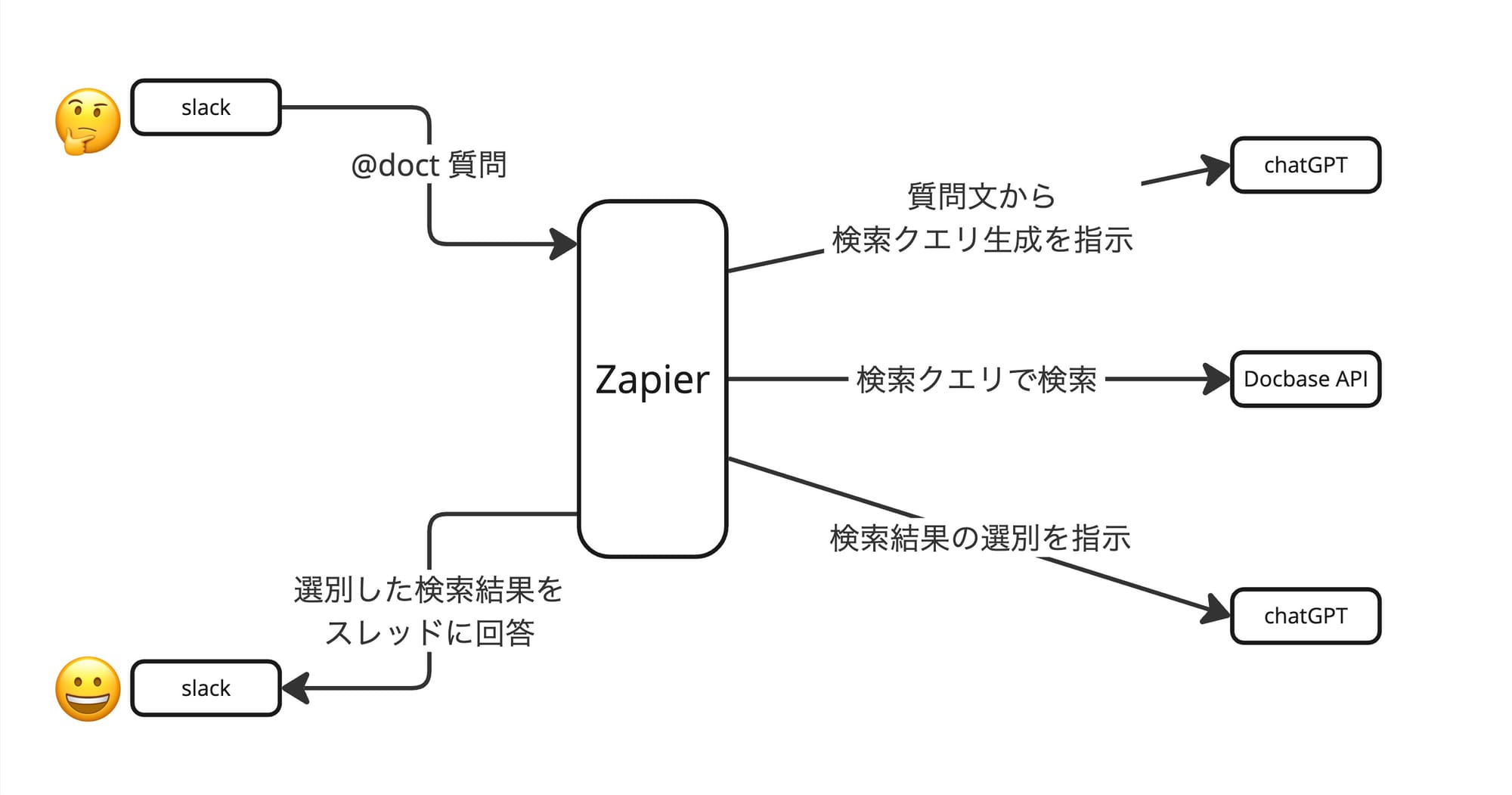
slackで特定のキーワード(例: @doct)をつけて質問をするとZapierのワークフローがトリガーされます。Zapierでの処理は主に3つです。
- ChatGPT に質問文から検索クエリ生成を指示
- DocbaseAPI をつかって検索クエリで検索
- ChatGPT に検索結果の選別を指示
あとの処理は3の回答を整形して slack のスレッドに書き込んであげるだけです。
全文検索のハックとRAGの比較
これらの処理についてRAGと比較して詳しく説明します。
大規模言語モデル(以下LLM)とドキュメントを紐づける一般的な方法としてRAGがあります。以下にRAGの簡単な仕組みを示しました。
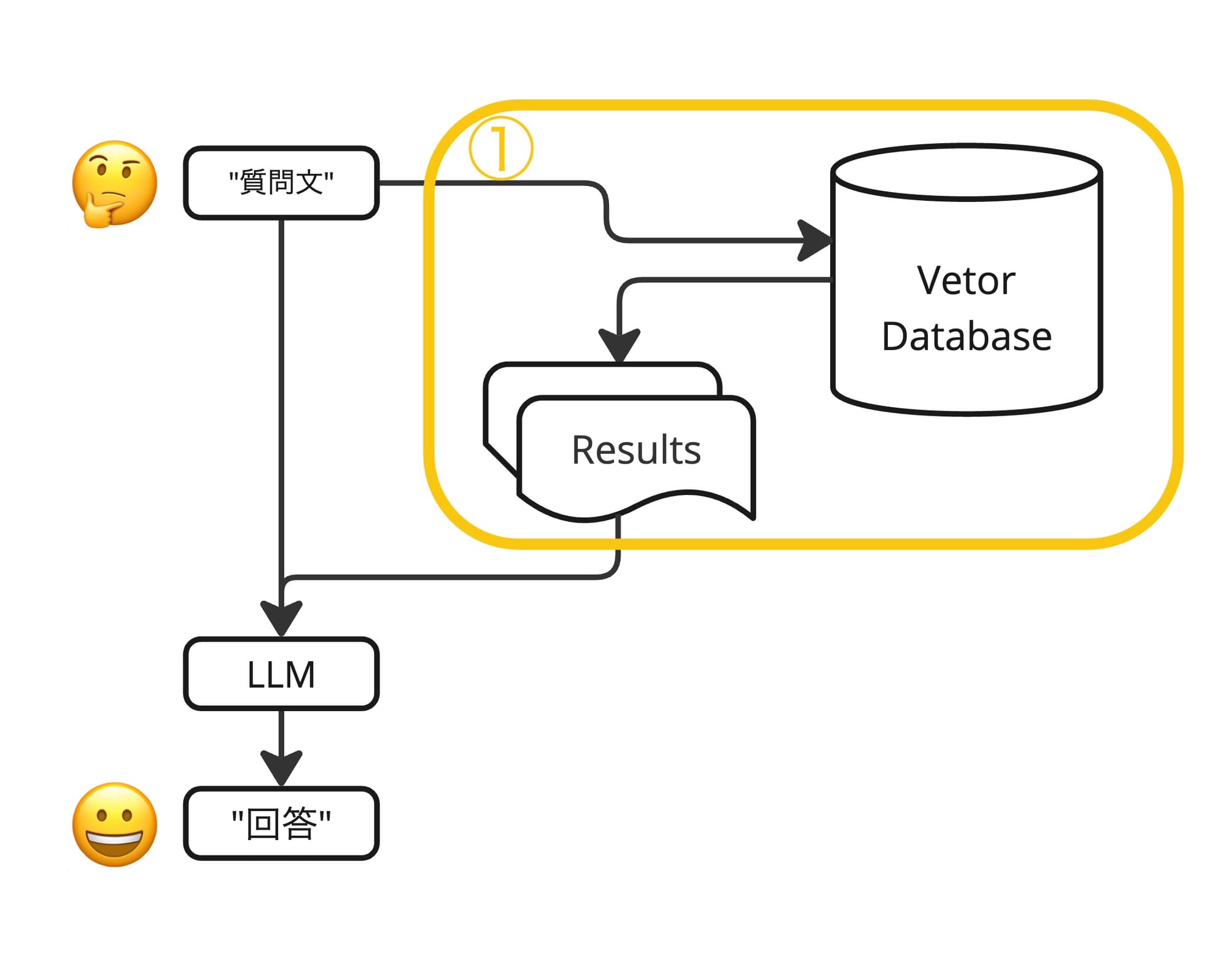
参考: https://platform.openai.com/docs/guides/optimizing-llm-accuracy#retrieval-augmented-generation-rag
ナレッジをベクターDBに保管しておき、質問文と関連性が高いナレッジと質問文それ自体をあわせてプロンプトをつくりLLMに回答を生成させることで、ナレッジをもとにした回答を行います。これにより具体的な社内ナレッジなどの知識を前提とした回答が可能になり回答の正確性が向上します。
今回のハックはRAG全体の模倣ではなくオレンジで囲った①の箇所、"関連文書検索"の箇所に対応しています。全文検索とLLMをつかって擬似的な関連文書検索を実現します。
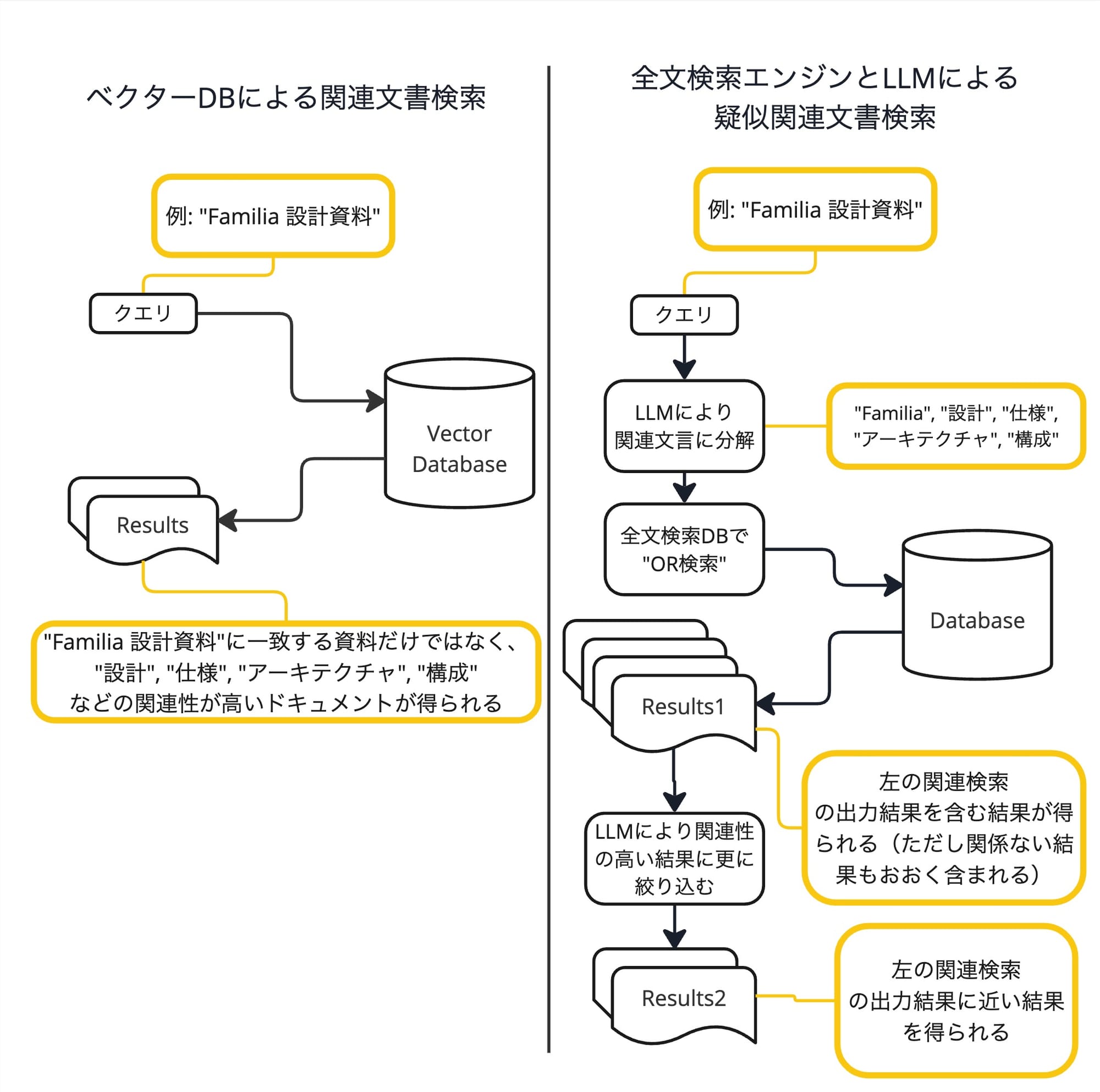
左に示したベクターDBによる関連文書検索はシンプルです。クエリを(ベクトルに変換する処理は必要かもしれませんが)DBに送ると関連レコードを得ることができます。
右側は複雑でみるからにあまりよくなさそうな感じがしますが、これが今回のハックのコアのコンセプトになります。
まず、検索文言をあらかじめLLMを使って関連文言に分解します。
eg. "Familia 設計資料" -> "Familia" "設計" "仕様" "アーキテクチャ" "構成"
その後、全文検索エンジンで関連文言のOR検索を行います。そうすると関連文書を含む"ひろめ"の結果が得られるので、そこから更にLLMに絞り込みを行わせることで目的の関連文書をゲットすることができます。
このハックのデメリットは一目瞭然ですね。構成が複雑であることLLMの呼び出しが2回必要であるため検索コストが高いことです。そのため関連文書検索のために素直にベクトルDBを構成したほうが良さそうにみえるかと思います。
しかしその反面、既に全文検索が使用できる環境であればベクトルDBの構築を行わずに済むことは大きなメリットです。LLMの呼び出しも ChatGPT API であればAPIの呼び出しを二回行うだけなのでオンデマンドの課金コストがかかるだけでイニシャルコストはかかりません。社内文書検索程度の利用頻度であれば意外とコスパがいい選択肢となりえます。
このコンセプトはRACCOONさんのテックブログで紹介されていた逆ベクトル検索と近いのでそちらも参考にしてください。同じようなことをしている人がいると知ってびっくりしました。実は2024年の2月にはボットは稼働してたので参考にして開発したとかではないのですが…(ブログ公開が遅くて今頃になってしまった)。
実装の詳細
Zapierで実装した処理にはslackによるトリガーなどもありますがそういう一般的な利用方法は Zapier のドキュメントなどでも説明されておりここで紹介する意味はないのでここでは前述した3つの処理について詳細に説明します。
- ChatGPTに質問文から検索クエリ生成を指示
- DocbaseAPI をつかって検索クエリで検索
- ChatGPT に検索結果の選別を指示
ChatGPTに質問文から検索クエリ生成を指示
slackから来た質問文をChatGPTのAPIに投げてDocbaseの検索クエリを生成させます。
プロンプトを作る
まずslackからのメッセージからChatGPTのAPIに送るプロンプトを作成する必要があります。
これをどうやって組み立てているかというと、実はCode by ZapierというZapierのビルトインツールをつかってJavaScriptで組み立てています。
「ノーコードとは何だったのか?」って思われると思いますが、Zapierについてノーコード(ローコード)と書いているのはこの伏線でした。文字列の組み立てなんかはコードを書いてしまったほうが早いのでこうしています。
ところでブラウザのChatGPTで4oモデルなどを選んで検索クエリを作成してくれと素直にお願いしてみると以下のような結果がかえってきます。このままではとても検索クエリとしては使用できない事がわかるかと思います。

そこでプロンプトを更に詳細にし目的の回答が得られるようにチューニングしていきます。(プロンプト千本ノックともいう)
完成したプロンプトが以下です。
社内文書データベースの検索単語を考えてほしいです。私が質問するのでそれに対してどんな単語で検索すれば良さそうか提案してください。
OR検索を行うため細かい表記ゆれを含めていただいても大丈夫ですが、検索範囲が大きくなり過ぎないように一般的すぎる単語は回答に含めないでください(含めない単語の例:マニュアル、議事録、ドキュメント、資料)。
例の質問と回答を参考にしてください。
回答する際には以下の規約に従ってください
- 回答は例のように単語の間に空白とORを入れた形式でお願いします
- ただし検索オプションと単語の間にはORは入れないでください
- 並び順を指定するオプション(例: "desc:likes" など)は複数設定しないでください
- また並び順はとくに指示がなければデフォルトで"desc:score"を設定してください
- author:のオプションを使用するのは特にアルファベットで作成者名を指定されたときだけにしてください。例: m.shigeru
- とくに議事録を指定されていない場合は末尾に" NOT tag:議事録 "をつけてください
例1: 質問: "どのDBに何のテーブルがあり、そのテーブルは何を意味するかみたいな早見表があれば、それを教えていただきたいです。
回答: "desc:score データベース OR データ OR テーブル OR 意味"
例2: 質問: "yamada_tarouの代表作"
回答: "desc:score author:yamada_tarou 代表作 OR 主要 OR プロジェクト OR 成果物 OR ポートフォリオ"
例3: 質問: "m.shigeru の人気がありそうな記事"
回答: "desc:likes author:m.shigeru"
質問: "{{ <質問文> }}"
全体的な特徴としてはあえて「日本語」でプロンプトを作成している点があるかと思います。英語にしたほうがトークンが節約でき利用料金が節約できるという明確な利点はあるのですが、メンテナンス性を考えると日本語でプロンプト作成したほうが圧倒的に良いと思います。
また性能に関してはgpt4以上のモデルでは英語でも日本語でも今回の用途だと違いを感じられません。
他には一般的なプロンプトテクニックも使用しています。
- (規約という形で)明確な指示を書く
- 例を挙げる
- 区切り文字を使用して入力の異なる部分を明確に示す
参考: https://platform.openai.com/docs/guides/prompt-engineering
逆に一般的でなく社内ドキュメントの状況に最適化した部分がこちらです。
とくに議事録を指定されていない場合は末尾に" NOT tag:議事録 "をつけてください
議事録が多すぎてノイズになってしまっているため目的のドキュメントにたどり着くためのノウハウを反映させています。こういう局所的なチューニングができるのは自作ツールの良いところですね。機械的にクエリを追加する手法を採用していないのは、「議事録からも探してほしい」のような指示に柔軟に対応するためです。
プロンプトをテストすると望んだ結果が返ってきました。

基本的にはこのプロンプトで十分利用可能なレベルです。しかしDocbaseさんのAPIには高度なオプションを設定できるためこれを活かしたい。しかし全パターンを考えて指示や例示に含めるのは大変です。
こういうときはどうすれば良いか。
そうです、プロンプトにドキュメントを全部つっこんでしまいましょう!
そして完成したのがこちらのプロンプトです。
>プロンプト
社内文書データベースの検索単語を考えてほしいです。私が質問するのでそれに対してどんな単語で検索すれば良さそうか提案してください。OR検索を行うため細かい表記ゆれを含めていただいても大丈夫ですが、検索範囲が大きくなり過ぎないように一般的すぎる単語は回答に含めないでください(含めない単語の例:マニュアル、議事録、ドキュメント、資料)。例の質問と回答を参考にしてください。
回答する際には以下の規約に従ってください
- 回答は例のように単語の間に空白とORを入れた形式でお願いします
- ただし検索オプションと単語の間にはORは入れないでください
- 並び順を指定するオプション(例: "desc:likes" など)は複数設定しないでください
- また並び順はとくに指示がなければデフォルトで"desc:score"を設定してください
- author:のオプションを使用するのは特にアルファベットで作成者名を指定されたときだけにしてください。例: m.tsuyoshi
- とくに議事録を指定されていない場合は末尾に" NOT tag:議事録 "をつけてください
例1: 質問: "どのDBに何のテーブルがあり、そのテーブルは何を意味するかみたいな早見表があれば、それを教えていただきたいです。"
回答: "desc:score データベース OR データ OR テーブル OR 意味"
例2: 質問: "yamada_tarouの代表作"
回答: "desc:score author:yamada_tarou 代表作 OR 主要 OR プロジェクト OR 成果物 OR ポートフォリオ"
例3: 質問: "m.shigeru の人気がありそうな記事"
回答: "desc:likes author:m.shigeru"
検索クエリについてのドキュメント
"""
### 検索オプション
|条件 | 検索オプション |
| --- | --- |
| タイトル | title:キーワード |
| 本文 | body:キーワード |
| コメント | comments:キーワード |
| 添付ファイル | attachments:キーワード |
| 投稿者 | author:ユーザーID |
| コメントした人 | commented_by:ユーザーID |
| グッジョブした人 | liked_by:ユーザーID |
| タグ | tag:タグ名 |
| タグ未設定 | missing:tag |
| スター | has:star |
| 共有済 | is:shared |
| アーカイブ済み | include:archive |
| 作成日 | 日付指定 `created_at:2018-01-01`<br>期間指定 `created_at:2018-01-01~2018-06-01`<br>指定した日付まですべて `created_at:*~2018-01-01`<br>指定した日付以降すべて `created_at:2018-01-01~*` |
| 更新日 | 日付指定 `changed_at:2018-01-01`<br>期間指定 `changed_at:2018-01-01~2018-06-01`<br>指定した日付まですべて `changed_at:*~2018-01-01`<br>指定した日付以降すべて `changed_at:2018-01-01~*` |
|検索結果の並び順 | スコア昇順 `asc:score`<br>更新日昇順 `asc:changed_at`<br>作成昇順 `asc:created_at`<br>スター数昇順 `asc:stars`<br>コメント数昇順 `asc:comments`<br>GJ数昇順 `asc:likes`<br>スコア降順 `desc:score`<br>更新日降順 `desc:changed_at`<br>作成降順 `desc:created_at`<br>スター数降順 `desc:stars`<br>コメント数降順 `desc:comments`<br>GJ数降順 `desc:likes
### AND・OR・NOT検索
複合検索(AND)、いずれかのキーワードで検索(OR)、除外検索(NOT)にも対応しています。
### AND検索
`キーワードA キーワードB`
2つの条件、どちらにもマッチするメモを検索できます。
上記の場合「キーワードAとキーワードBを含む」メモになります。
### OR検索
`キーワードA OR キーワードB`
2つの条件のどちらかにマッチするメモを検索できます。
上記の場合「キーワードA、またはキーワードBを含む」メモになります。
### NOT検索
`キーワードA -キーワードB`
特定の条件に該当しないメモを検索できます。
上記の場合「キーワードAを含むが、キーワードBは含まない」メモになります。
"""
質問: "{{ <質問文> }}"
実際の検索オプションのドキュメントから不要なところを省いてすこし短くなっていますが、それでも近年プロンプト長をかなり長く設定できるようになってきたため実現できる技といえます。
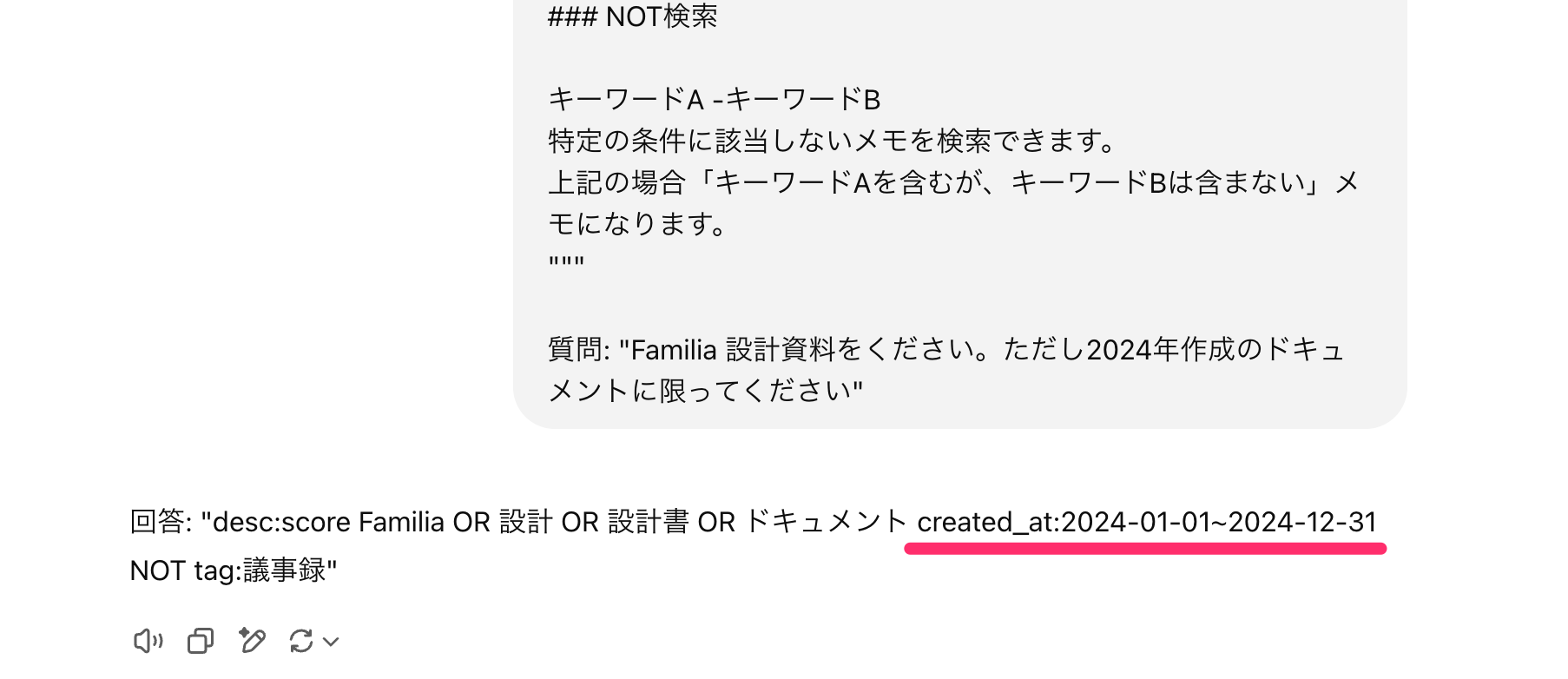
この工夫をすることで例えば以下のように期間指定を自然な文章で指示すると的確なクエリを作成してくれます。APIの仕様を理解していないとこんなことはできません。ChatGPTすごいですね。
完成したコードはこんな構成になります。
// Code by Zapier
const question = inputData['question'];
const prompt =
'<プロンプト>\n\n' +
'質問: "' + question + '"'
output = [{prompt}];
ChatGPT APIに投げる
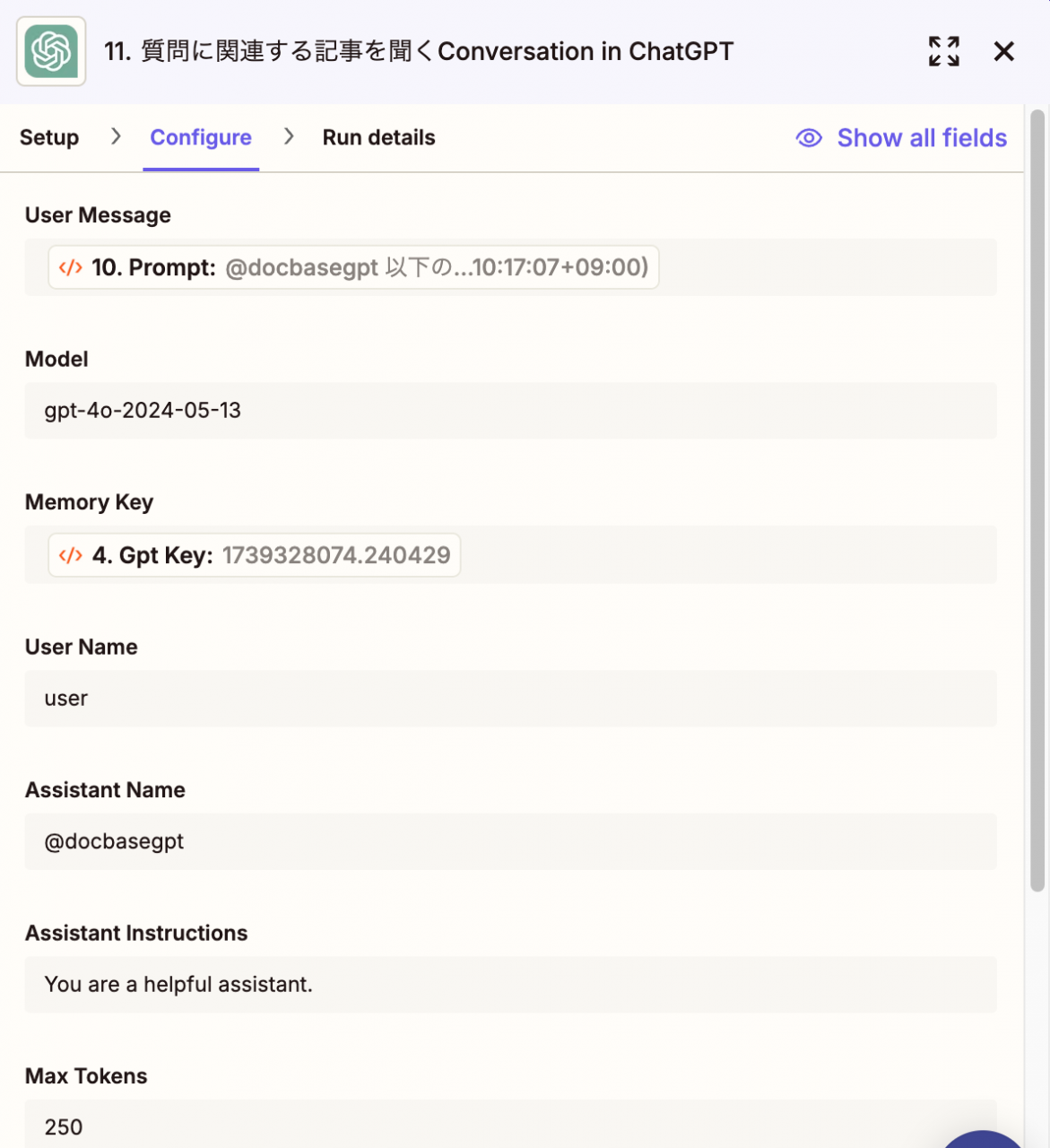
やり方としてはZapierにChatGPTのツールがあるのでそれを活用するだけです。アカウントの設定が必要ですがOpenAIのAPI keyの設定だけで使用できるようになります。
https://zapier.com/apps/chatgpt/integrations
使用するモデルはこの程度のタスクでもgpt4以上の精度はあったほうが良いです。応答速度を考えると4oがおすすめです。またトークン数はプロンプトの分量によっては上げる必要があるかもしれませんが最近はデフォルトで 1024 に設定されるようなので、そのままで問題ないことが多いでしょう。
(画像ではMemory Keyも設定していますが、インタラクティブに応答するわけではないので今回の場合不要です)
DocbaseAPI をつかって検索クエリで検索
前段で生成した検索クエリでDocbaseAPIにリクエストを送りドキュメントのリストを取得します。
出力結果の調整
前項で作成されたクエリは余計な文字も含まれた形式になっているためDocbaseAPIに投げる前に微調整を行います。またセキュリティ上の制限もこの段階で設定します。
調整前
回答: "desc:score Familia OR 設計 OR 設計書 OR ドキュメント NOT tag:議事録"
Code by Zapierによる調整後
group:全員 desc:score Familia OR 設計 OR 設計書 OR ドキュメント NOT tag:議事録
ここで行っているのは2つあります。
- 回答形式に含まれる余計な文字を取り除く「回答」「"」など
- 検索範囲を全員が閲覧可能なドキュメントに絞る
後者が実は重要なのですが、弊社の社内ポリシーとして「個人情報のような極秘情報はChatGPTのAPIにも送信しない」という決まりとなっているため、全社公開されていない極秘情報は検索結果から取り除くことにしています。
プロンプトにわたしたドキュメントにはgroup:<name>の記法についての記述を取り除いています。この調整の段階でクエリを先頭につけてしまうことで、問答無用で検索結果に制限をかけることができます。
>詳細なコード
// this is wrapped in an `async` function
// you can use await throughout the function
const originalQuery = inputData['originalQuery'] ;
// replaceAllを何度も使っているが
// LLMの回答には多少ブレがあるのできれいに正規表現で抽出するより実はこのような汚く見える方法がよい
let query = originalQuery.replaceAll('回答: ', '')
.replaceAll('"', '')
// 検索範囲を全員に絞るため重要
let customQuery = 'group:全員 ' + query
output = [{query: customQuery}];
Docbase APIへのリクエスト
Webhooks by Zapierというツールを使用してHTTPリクエストを設定します。
残念ながらプレミアムの機能ですが、プログラマの方ならCode by Zapierの中でNodejsのfetchAPIが使用できるはずなのでそれを試してみてください。プログラマでなければ課金をおすすめします。
APIの仕様についてはDocbase側のドキュメントがあるので参考にしてください。
https://help.docbase.io/posts/92984
検索クエリ(q)に先程作成したクエリを設定し、ほかにはper_pageのクエリパラメータを30に設定してください。
ChatGPT に検索結果の選別を指示
最後に検索結果からプロンプトを作成し、再度ChatGPTのAPIにリクエストを投げてはじめの質問に対して関連性の高そうな結果を選別して回答させます。
プロンプトの作成
DocbaseAPIのレスポンスはドキュメントの例にあるようにpostsという配列で返ってきます。
今回はこのレスポンスの中から以下の値のみを使用してプロンプトを作成します
- 'title'
- 'url'
- 'user.name'
- 'created_at'
// プロンプトサンプル
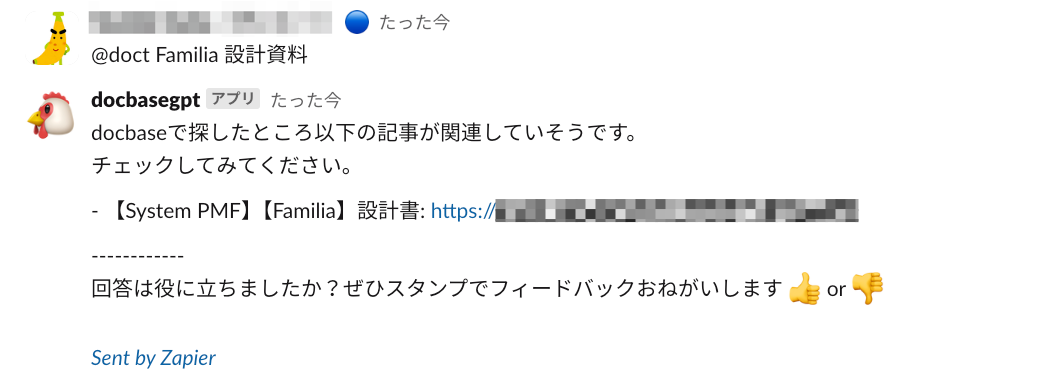
@docbasegpt
以下の記事タイトルとそれに対応するURLのリストのなかで、質問の回答に関係しそうなものがあればそれを回答してください。回答はリストのみとしてください。
質問: @doct Familia 設計資料
記事リスト:
- 【System PMF】【Familia】設計書: https://yyyyyyyy.docbase.io/posts/xxxxxx(作成者:xxxx.xxx, 作成日: 20xx-11-02T11:36:59+09:00)
- 【Familia】要件定義書: https://yyyyyyyy.docbase.io/posts/xxxxxx (作成者:xxxx.xxxx, 作成日: 20xx-09-26T14:02:05+09:00)
- System PMF: https://yyyyyyyy.docbase.io/posts/xxxxxx (作成者:xxxxx, 作成日: 20xx-11-28T16:33:10+09:00)
- 障害対応フロー: https://yyyyyyyy.docbase.io/posts/xxxxxx (作成者:xxx, 作成日: 20xx-10-24T17:42:09+09:00)
- 信用取引とは?: https://yyyyyyyy.docbase.io/posts/xxxxxx (作成者:xxxx.xxxx, 作成日: 20xx-11-08T13:56:29+09:00)
<省略>
- App 機能一覧: https://yyyyyyyy.docbase.io/posts/xxxxxx (作成者:xxxxxxxx, 作成日: 20xx-02-16T16:38:37+09:00)
冗長なのでコードを共有するか迷ったのですがZapierの配列の扱いにクセがあったりして参考になるかと思いますので一応コードをのせておきます。実際に手を動かして作られる方などは参考にしてください。
>詳細なコード
事前に前段のFormatterアクションでタイトルを文字列化します。
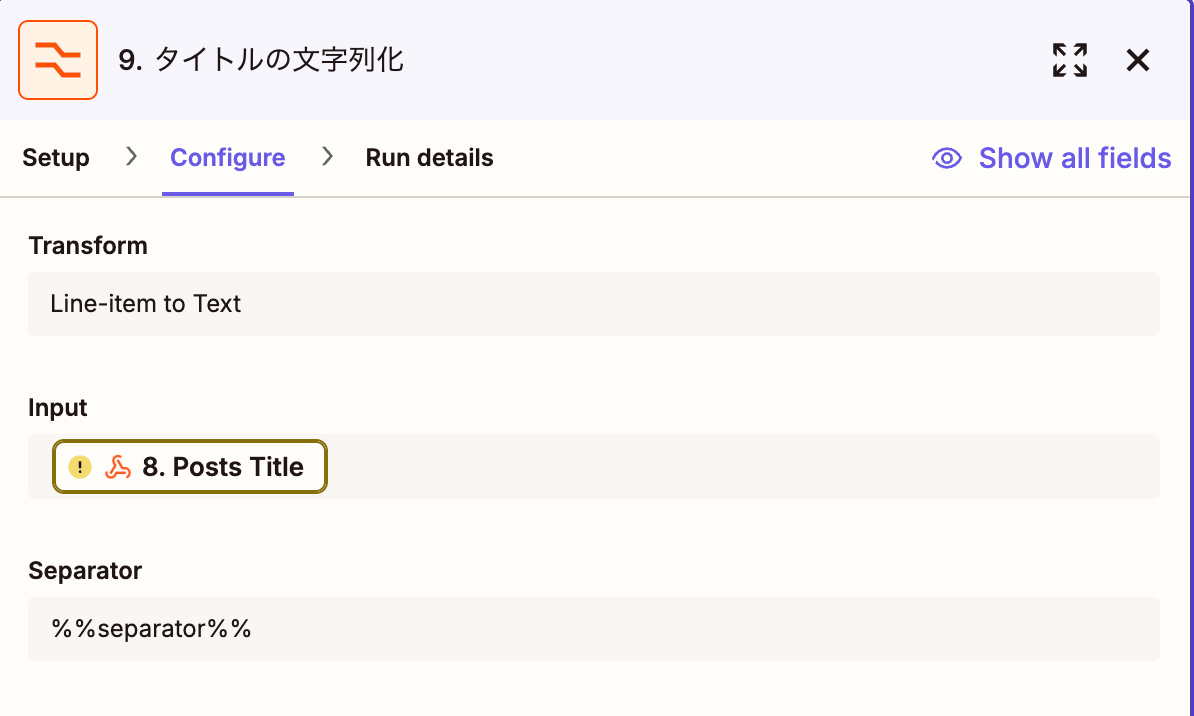
なぜこんなことをするのかというと、Zapierの仕様のようなのですが、配列の結果をCode by Zapierで利用しようとするとコンマ(",")でつながった文字列としてしか取得できない問題があります。自由入力のタイトル内には当然コンマがはいる事があるため、そのようなタイトルがひとつあるだけで配列を正しく扱うことができなくなってしまいます。
そこで苦肉の策として普通は使わないような文字列をセパレータ(%%separator%%)として定義して文字列化したのち Code内でJavaScriptの配列に変換するという二度手間を行っています。
そのあとのCodeアクション内のプロンプト作成の実装の内容は以下のようになります。
// Code by Zapier
let titles = inputData['titles'];
let urls = inputData['urls'];
let authors = inputData['authors'];
let times = inputData['times'];
titles = titles ? titles.split('%%separator%%') : [];
urls = urls ? urls.split(',') : [];
authors = authors ? authors.split(',') : [];
times = times ? times.split(',') : [];
const question = inputData['question'];
// タイトルとURL、作者、時間の配列長さは同一の想定
if(titles.length !== urls.length || titles.length !== authors.length || titles.length !== times.length) {
throw new Error('Invalid arrays!?titles: ' + titles.length + 'url: ' + urls.length + 'authors: ' + authors.length + 'times: ' + times.length);
}
let titleUrls = titles.map((t, i) => ({ title: t, url: urls[i], author: authors[i], time: times[i] }));
let titleUrlListString = titleUrls.map((item) => '- ' + item.title + ': ' + item.url + ' (作成者:' + item.author + ', ' + '作成日: ' + item.time + ')' ).join('\n')
const prompt =
'@docbasegpt\n' +
'以下の記事タイトルとそれに対応するURLのリストのなかで、質問の回答に関係しそうなものがあればそれを回答してください。回答はリストのみとしてください。\n\n' +
'質問: ' + question +'\n\n' +
'記事リスト:\n' + titleUrlListString
output = [{prompt}];
ChatGPT APIへのリクエスト
ここでは先程と同じようにZapierのChatGPTのツールを利用して先ほど作成したプロンプトを送るだけです。
30件の記事リストからChatGPTが選別した記事を返答してくれました。

活用事例
直近の測定では30日間で70件ほどの利用頻度で利用されていました。どんな活用がされているかを改めて調べてみました。
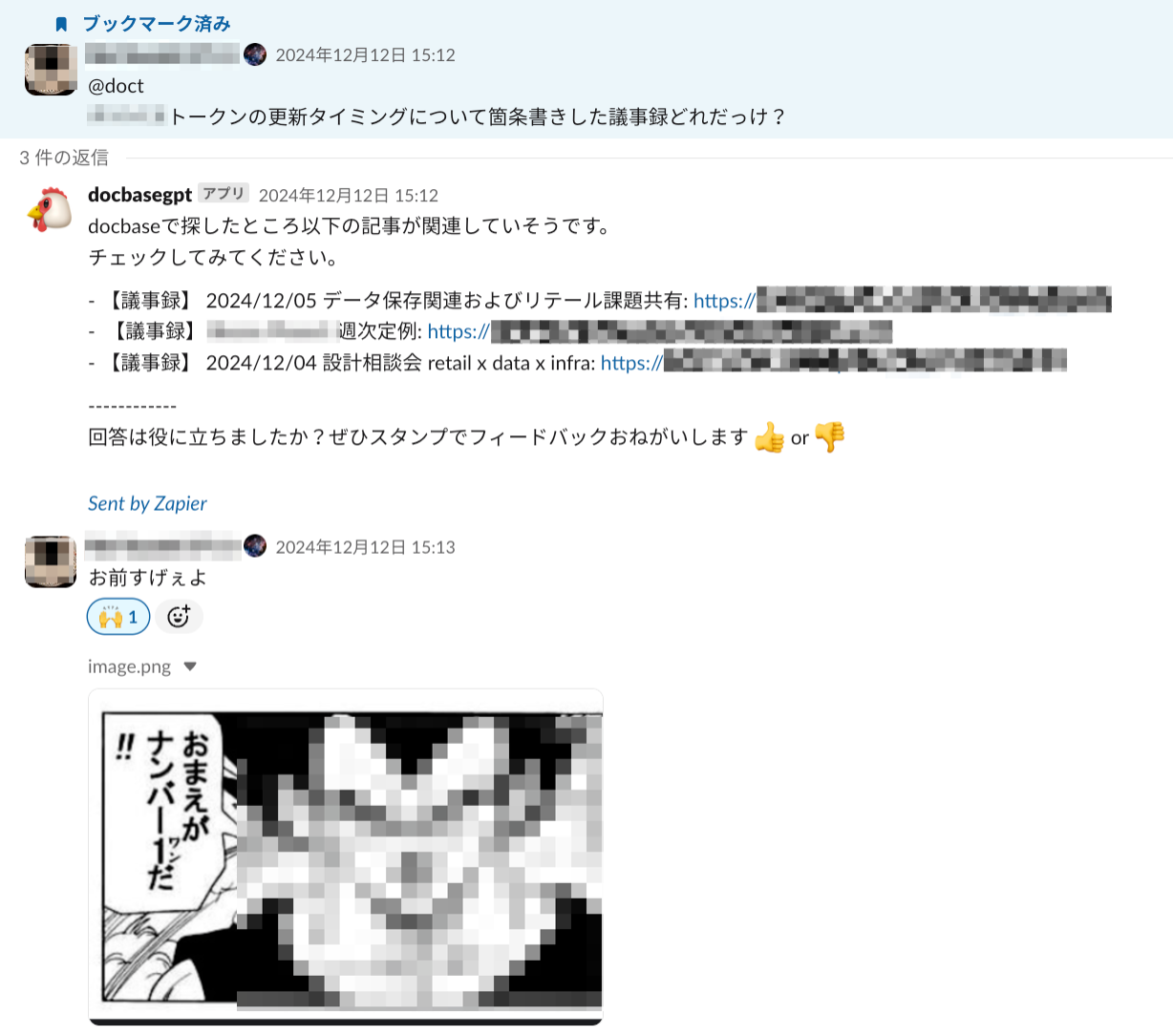
普通に探したら虱潰しに中身を見るしかないようなドキュメントを見つける
「あの話どこの会議で話してたっけ?」なんてことたまにありますよね。そういう資料をピンポイントで見つけてきてくれると非常に時間と手間を短縮できて嬉しいです。
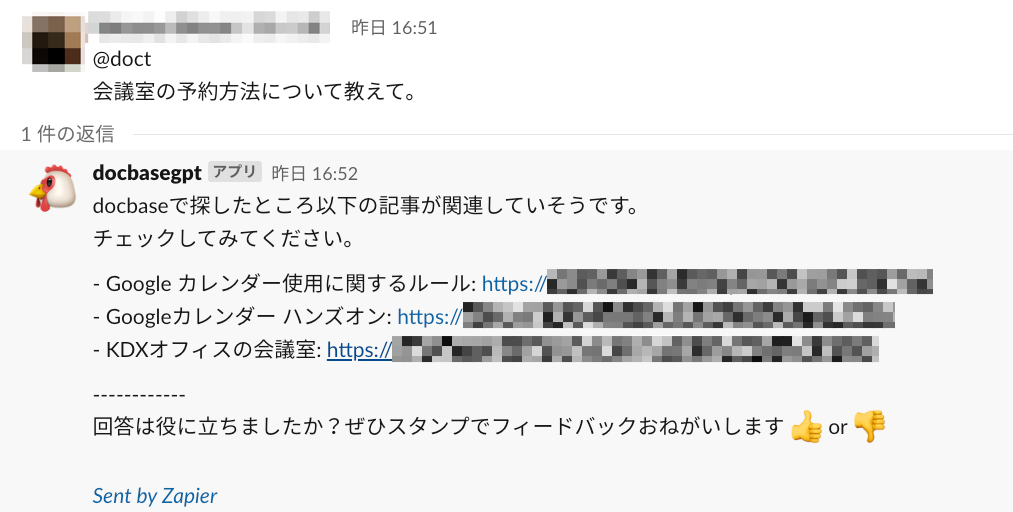
うろ覚え系
人間、資料の存在は覚えていてもうろ覚えということはよくあります。そういう場合も自然言語でボットに聞けばすぐ回答がもらえます。

人間の同僚になんども聞くのが憚られる質問でもボット相手なら気にせず何度でも聞けるのでうれしいですね。
付録
ノーコード(ローコード)を採用する利点
ノーコード(ローコード)の利点については色んなところで書かれていると思いますが今回特に感じた点を書いておきます。
- SaaS間の連携が楽にできる
- 少し複雑なことをしたい場合はJavaScriptやPythonでコードを書くことができるので意外と自由度が高い
- クレデンシャル情報の管理が楽
- システムのアーキテクチャが一目瞭然なのでメンテナンスが比較的楽で引き継ぎもしやすい
ローコードツールはZapierだけでなく類似したサービスにn8nなどもあります。n8nもパワフルなツールなので是非活用してみてください。
slackをインターフェースとして採用する利点
これは想定していなかったのですが、slackをインターフェースとして採用すると社内コミュニケーションの活性化につながるという利点があります。
典型的な例では、ボットがうまく回答できないときにそれを見た他の人がかわりに回答してくれることがありました。
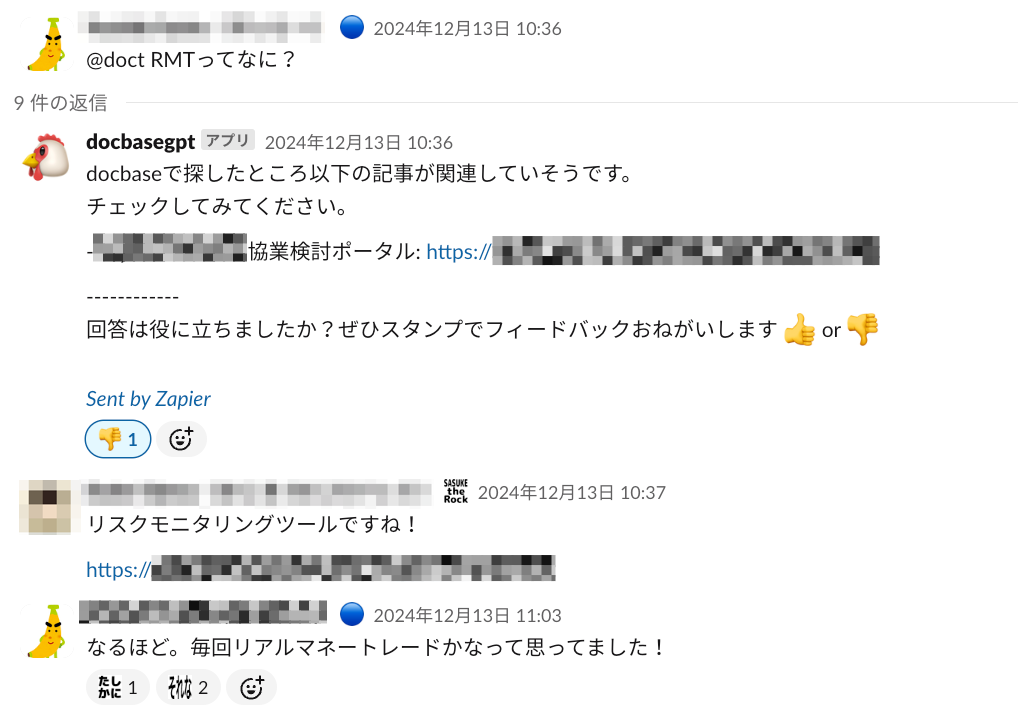
Bitbankはフルリモートなので、その人がなにを探しているか、何に困っているかがオープンになることがけっこう重要だと考えています。その点slack上でボットとのやり取りがあればその人が何をしているのかは一目瞭然です。
その他にもいろいろ利点があります
- うまく回答できていない場合すぐにボットの改善につなげることができる
- 必要なドキュメントがそもそもない場合に担当者がそのドキュメントを作ってしまうことでドキュメントの充実につながる
ここであげたものは全部ChatGPTのインターフェースで調べるだけでは得られない利点といえるでしょう。
セキュリティとプライバシーの考慮
社内文書ならではのリスク管理は必要です。
今回の事例では前述のようにChatGPTのAPIには社内全体公開のドキュメントの情報のみ渡しており機密性の高い情報は渡さないようにしています。また現状ではタイトルのリストだけから選別を行うため文章の内容すら渡していません。
通常社内データを渡すSaaSが増える場合は社内審査が必要になるかと思いますが、こういうやりかたにすればノーコードツールを既に導入しているところであれば考慮するべき点は比較的少なくできるかなと思います。
とはいえ今回のボットを作成する際には社内のコンプライアンス担当部署に確認を取って進めています。
まとめと今後の展望
ChatGPTにまとめてもらいました。なかなかよかったのでそのまま転記します。
この記事では、社内文書検索を効率化するために、Slackボットを利用し、ChatGPT APIとZapierを活用したシンプルなツールを構築した方法を紹介しています。
増え続ける社内ドキュメントの中で目的の情報を素早く見つける課題を解決するため、ChatGPTを使って検索クエリを自動生成し、その結果をSlack上で提示する仕組みが紹介されています。
また、ノーコードツールのZapierを活用することで、システム開発のコストや手間を大幅に削減し、さらにSlackをインターフェースにすることで社内コミュニケーションの活性化にも寄与しています。
今後の展望
今後の可能性として記事のリンクを回答するのではなく、質問に対する回答を直接生成するRAGタイプへの発展もありえると思っています。ただその場合ドキュメントが見当違いだったり「無かった」場合の嘘回答(ハルシネーション)の抑制や検知はけっこう難しそうなのでセンシティブな社内業務にいきなり使ってもらうのは難しいかもしれません。
横展開してナレッジのリソースをもっと増やす方向は良いのではないかと考えています。Google Documentやslackの過去ログなどは社内ナレッジの宝庫なのでこれらを対象にしたいと考えています。それぞれの特性に合わせたチューニングがまた必要になってくるでしょう。

