
まえがき
はじめまして、データチームの加藤です。
普段はビットバンクでデータエンジニアとしてデータ基盤の運用管理や新規開発を行っています。
現在ビットバンクではAmazon Redshift上にデータ基盤を構築しており、エンジニア・データ分析者だけでなくビジネス部門含めた従業員がこのデータ基盤を利用しています。今回はこのデータ基盤にSaaSから取得したデータや、REST APIで取得した外部のデータを取り込むためのデータパイプラインを構築したプロジェクトについて紹介します。
この記事では、以下について記載しています。
今後データパイプラインを構築する際にひとつの方法として参考にしていただければと思います。
- ビットバンクのデータ基盤の現状について
- データ基盤にデータパイプラインの導入プロジェクトについて
- アーキテクチャで工夫した点
- まとめ
ビットバンクのデータ基盤の現状
全社的にAWSを中心にシステムを構成しており、私が所属するデータチームでもAWS上にデータ基盤を構築しています。アプリケーションではAmazon Auroraを利用しているためAuroraからFederated Queryを利用して Redshift(DWH)にデータ格納を行いDataSharing機能を用いて必要なデータのみを共有することで、用途毎にデータマートとして安全に全社員が利用できる基盤となっています。また、全社でBIツールとしてRedashを導入しているのでビジネス部門の方々はRedashを通じてデータの抽出や分析を行っています。
また、ビットバンクではデータ分析を専門に行うチームがあり、このチームメンバーはAmazon SageMakerで構築された分析環境を利用しています。
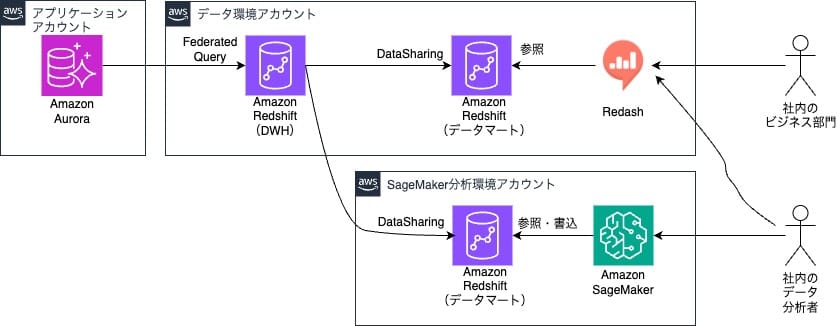
しかし、このデータ基盤には課題が大きく2つありました。
1つ目はアプリケーションで生成しているデータ以外のデータをデータ基盤に取り込める仕組みが用意されておらず、ビジネス部門がRedashから一元的にデータを取得することができていない状況でした。
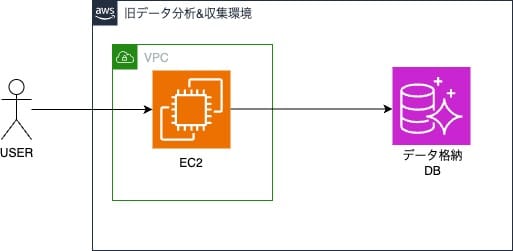
2つ目は旧来から利用されていたデータ分析&収集環境があり、この環境で取得していたデータをSageMaker分析環境に統一して利用したいという要望が以前からあったため、今回合わせて実施することにしました。
データパイプライン構築プロジェクトの詳細
これらの課題を解決するために次の2つのことを本プロジェクトのスコープとし、Redshiftにデータ連携するためのデータパイプラインを構築しました。
- 外部のデータを取得し統一的にデータ基盤に取り込む仕組みを用意する
- Amazon SageMaker分析環境でもデータ取得・加工をおこなえるようにし、統制の取れている環境でデータの取得から分析業務を行えるようにする
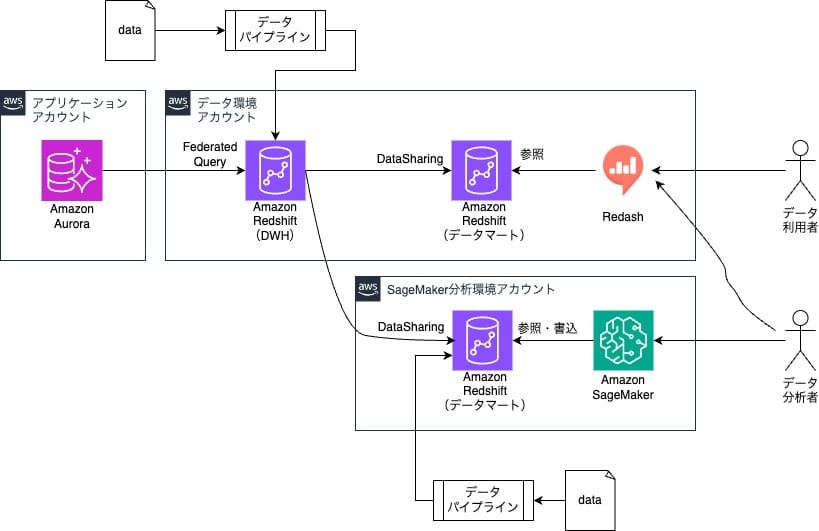
データパイプラインを構築することにより課題であったアプリケーションで利用しているデータ以外の外部データをデータ基盤に取り込む仕組みが作られるようになります。また、旧データ分析&収集環境で行っていたデータ収集を統制のとれているSageMaker分析環境でも実現できるようになります。
ここではデータパイプラインとしてStep Functionsを選定した理由とアーキテクチャについて記載していきます。
Step Functionsを選定した理由
今回新たにデータウェアハウスであるRedshiftに各データを取り込むデータパイプラインを構築する際に、実行基盤としてAWSと親和性が高いものを重視しデータパイプラインツールを選定しました。
はじめにdigdagやLuigiといったOSSのワークフローエンジンをEC2やECSで稼働させることを考慮しましたが、EC2やECSではOSやコンテナエージェントのバージョンアップといったリソースの管理・運用コストが発生することが予想されたためスピーディにプロダクトを提供していきたいという思いと、今後Redshiftへの取り込みを行うデータが増えていった際にもCloudFormationでリソース管理することで横展開が容易にできるという理由から、ビットバンク社内で既に利用されており知見があったAWS Step Functionsを採用しました。
アーキテクチャについて
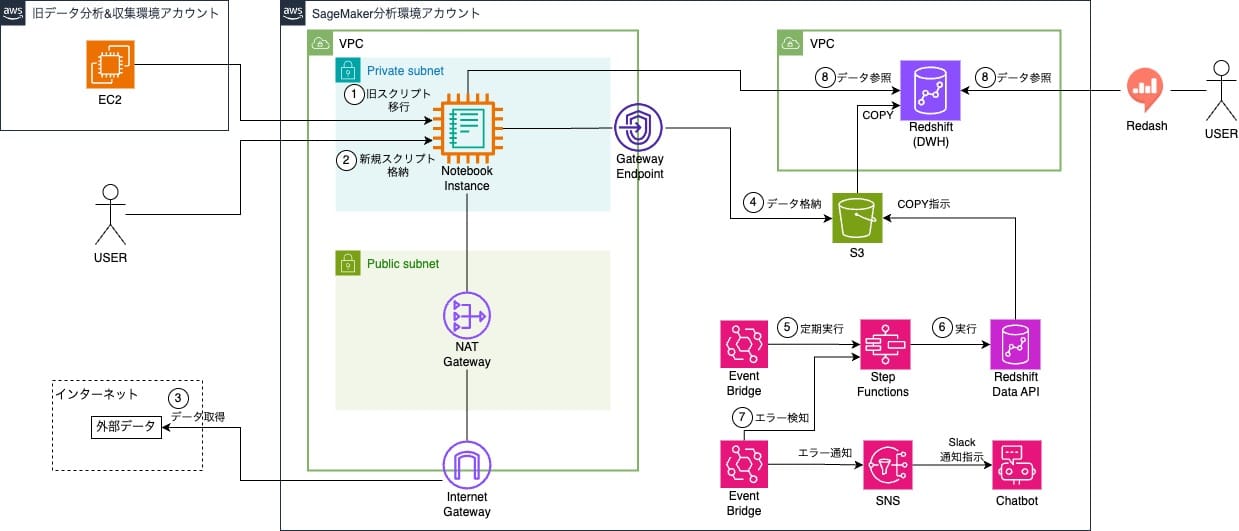
1. データ環境Redshiftに格納するデータパイプライン
データ環境アカウント以外のセキュリティレベルが異なるアカウントやサービスからのデータも一元的に管理するためにデータ基盤に連携するデータを集めるAWSアカウント(データ収集アカウント)を新たに作成し、そのアカウントのS3バケットから定期的にデータをRedshiftに格納するデータパイプラインを作成することにしました。
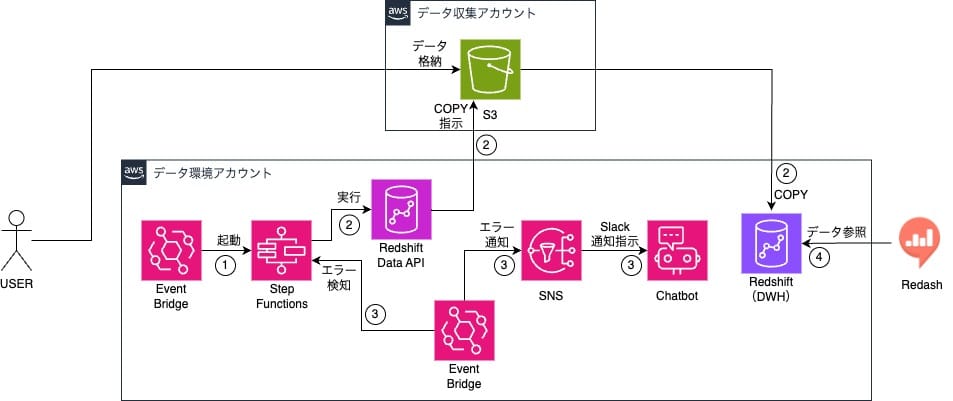
Redshiftに連携したいデータをデータ収集アカウントのS3バケットに格納し、日次でRedshiftへの連携を行います。
具体的な動作は以下の流れです。
- EventBridge Ruleを利用し、定期的にStep Functionsを実行
- Step Functions内でRedshift Data APIを利用しデータ収集アカウントS3バケットのデータをRedshiftに格納する
- EventBridgeでStep Functionsのステータスを監視し、ERRORが発生したらSNS→ChatbotからSlack通知を行う
- ユーザーはRedashからデータを利用する
2. SageMaker分析環境のRedshiftに格納するデータパイプライン
旧分析環境ではデータ分析者はEC2インスタンスにデータ収集・加工スクリプトを格納し、cronでスクリプト実行していました。
このデータ収集・加工スクリプトは以下3つに分類できます。
- 毎分実行でタイムスタンプが重要なもの(起動時のタイムラグが許されない)
- プロセス常駐で常に動いているもの(ストリームでデータ取得している)
- 日次や月次で起動時のタイムラグが許容されるもの
当初はSageMaker Notebook Jobを利用してスクリプト実行しようとしましたが、数秒で完了するスクリプトでもジョブ起動から実際に処理が走るまで数分掛かってしまい、上記「1」の種類のスクリプトには使えないことが判明しました。AWS Lambdaを使うことも考えましたが、上記「2」の種類のスクリプトでは使えず、管理運用の観点から極力同じ方法でスクリプトを実行したいという要望は満たせませんでした。
そこでSageMaker上にNotebook Instanceを立てて、このインスタンスにcron設定を入れてスクリプト実行することにしました。
詳細な流れについて以下に記載します。
- SageMaker Notebook Instanceを構築し、cron設定とデータ収集・加工スクリプトを旧分析環境EC2インスタンスからSageMaker Notebook Instanceに移植する
- 今後作成するスクリプトはSageMaker Notebook Instanceに格納していく
- SageMaker Notebook Instanceが配置されているVPCにInternet Gatewayを作成し、インターネットから外部のデータを取得する
- スクリプトで収集したデータをS3に格納する
- EventBridge Ruleを利用し、定期的にStep Functionsを実行
- Step Functions内でRedshift Data APIを利用し、S3のデータをRedshiftに格納する
- EventBridgeでStep Functionsのステータスを監視し、ERRORが発生したらSNS→ChatbotからSlack通知を行う
- ユーザーはRedashからデータを確認したり、SageMakerからデータを利用したりする
5~7についてはデータ環境アカウントに構築するStepFunctionsを利用したデータバイプラインを流用することにしました。
データパイプラインを構築する上で工夫したこと
アーキテクチャの詳細について書いてきましたが、その中でもStep Functionsを用いて実装する上で今回工夫した点を取り上げようと思います。
Step Functions上で前日の日付を取得する方法
「Redshiftへ格納するのは実行日の前日分のデータを全対象とする」という要件がありました。しかし、Step Functionsでは日付を操作する組み込み関数が存在しておらず、データが収集されているS3バケットから前日分のデータのみを対象とすることができませんでした。そのためStep Functionsから呼び出せるリソースで前日日付を取得する方法を調査しました。
Step Functionsで前日の日付を取得する方法のひとつとしてAWS Lambdaを利用して前日の日付を取得する実装方法が挙げられますが、Lambdaだとランタイムのアップデートなどの管理が定期的に必要なため今回はあえて使わず、Step FunctionsのトリガーとなるEventBridgeから渡されるパラメータを利用して実装しました。EventBridgeからStepFunctionsを実行すると次のようなパラメータが渡されます。
{
"version": "0",
"id": "[ID]",
"detail-type": "Scheduled Event",
"source": "aws.events",
"account": "[AWSアカウントID]",
"time": "2023-11-15T21:00:00Z",
"region": "ap-northeast-1",
"resources": [
"arn:aws:events:ap-northeast-1:[AWSアカウントID]:rule/[EventBridge Rule名]"
],
"detail": {}
}
このパラメータの中の「time」の値がUTCの実行時間となっており、日本時間の午前8時59分までにEventBridgeを実行すれば日本時間でみた前日日付を文字列で取得でき、今回の要件を満たしたため採用しました。
S3のPATH設計の共通化
収集したデータを格納するS3は次のような階層で設計して共通化しています。
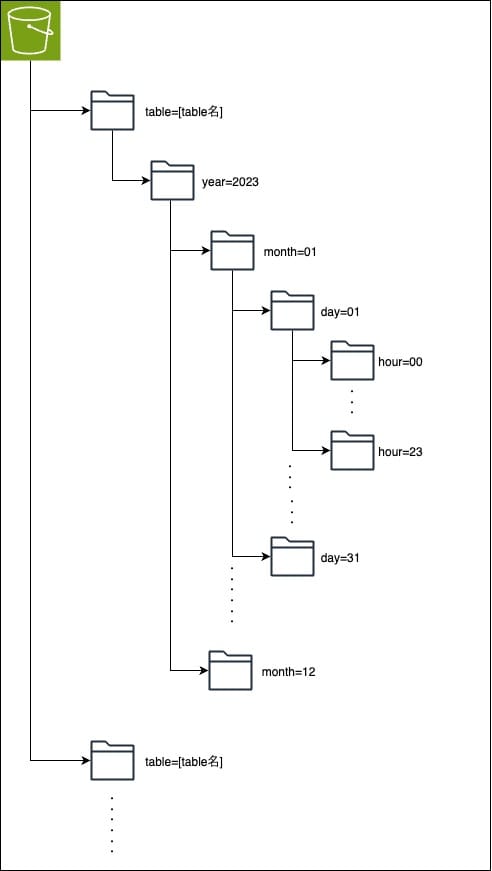
list_objects_v2などのAPIを実行する際に一度のリクエストで1000件までしか取得できないというAWSの仕様があるため、1000オブジェクト以下になるよう「hour」単位まで階層を分け、S3ではオブジェクトキーがプレフィックスによって分散されるため、オブジェクトにアクセスする際のパフォーマンスが向上するというAWSのベストプラクティスに沿って「key=value」の形でのPATH設計としています。
また、Step Functionsが様々なAWSのSDKをネイティブにサポートするようになったおかげでRedshift Data APIを直接実行でき、他AWSリソースを使わずシンプルなアーキテクチャになりました。
COPY [テーブル名] FROM 's3://[バケット名]/table=[テーブル名]/year=[Year]/month=[Month]/day=[Day]/' iam_role 'IAM Role ARN' delimiter '[Delimiter]' [圧縮方式] [ファイル形式];"
階層を共通にすることでStep Functions内のRedshift Data APIで実行している「COPY」コマンドを上記PATHの各階層の要素を当てはめることができ、様々なデータに対して共通のAWSリソースでデータウェアハウスであるRedshiftまでデータを格納することができるようになりました。
AWSTemplateFormatVersion: 2010-09-09
Parameters:
AccountId:
Type: String
StateMachineName:
Type: String
Extention: # 拡張子
Type: String
Decompression: # 展開(解凍)
Type: String
SchemaName:
Type: String
TableName:
Type: String
BucketName:
Type: String
IamRoleArn:
Type: String
Resources:
# Step Functions StateMachine
DataLoadExecuteStepFunctions:
Type: AWS::StepFunctions::StateMachine
Properties:
StateMachineName: !Ref StateMachineName
RoleArn: !Ref CommonIamRoleArn
--- 省略 ---
construct_sql_sentence:
Type: Pass
Parameters:
# Year, Month, Dateはステートマシンの前ステップで定義済み
SqlString.$: !Sub "States.Format('COPY ${SchemaName}.${TableName} FROM \\'s3://${AccountId}-${BucketName}/table=${TableName}/year={}/month={}/day={}/\\' iam_role \\'${IamRoleArn}\\' delimiter \\',\\' ${Decompression} ${Extention};', $.Year, $.Month, $.Date)"
Next: ExecuteStatement
また、S3のPATH以外にもデータ収集ファイルのデリミタや圧縮方式、ファイル形式などもCloudFormationの設定ファイルに変数として記載することでデータ毎に変えることができるような柔軟性も持たせるようにしました。
まとめ
今回のプロジェクトではRedshiftに格納していくデータパイプラインをStep FunctionsとRedshift Data APIを用いて構築することができました。今後増えていくデータに対してはCloudFormationでIaC化されたStep Functionsをはじめとした各AWSリソースを横展開できるようになり、新しいデータをデータ基盤へ取り込むことが容易になりました。また、データ分析を専門に行うチーム向けのSageMaker分析環境に外部からのデータを取り込むデータパイプラインを用意することでデータ分析者の分析の幅を拡げることができました。
しかし現時点ではいくつか問題があります。Redshiftに取り込む前日分のデータがすべて格納される時間が日本時間AM9時以降である場合に対応できなかったり、Step Functionsの処理が途中で止まってしまった際にリトライが難しいという課題があります。
今後はこのような課題を解消できるようにパイプラインの改善を行っていきたいと思います。
データチームではデータ分析者の人たちだけでなく全社で使われるデータ基盤を作っており、一緒に様々な課題を解決していきたい人を募集しています。
ここまでお読み頂きありがとうございました。

