
This is the second half of my 2 blog posts.
- Part1: Signal app, ABC, Lightning, and the future of the web
- Part2: Techblog: How Signal group chat works and how it integrates with Lightning ... This post
In the previous article, I explained how authentication works using attribute-based credentials and why anonymous web applications such as Signal are attracting attention.
In this article, I will explain how Signal uses anonymous credentials to ensure the anonymity of group chats and how the Lightning Network (LN) plays with it.
Since this document is just my understanding of the protocol, you may want to reference the original paper.
Finally, I will also explain why this kind of mechanism will be important for IT systems in general in the future. (The content of this document is quite technical, so you may want to skip to the last.)
Anonymity in group chats
When a user creates a group of multiple people in an application, the information is often stored on the server in the plaintext.
For security reasons, users should not get the information of the group without authenticating and proving that they belong to the group.
The problem with such a system is that even if the server adds a malicious user to the group, it is difficult for the user to verify it.
Thus it is disasterous in terms of anonymity.
If you want to hide/verify the group membership information, the conventional method is to let the user's client hold the group status without any information on the server, but this method has a drawback that it is difficult to manage the consistency of the group status among users.
Therefore, the new Signal protocol takes the approach of keeping the group information encrypted on the server, while granting permissions on the group through anonymous credentials.
How Signal uses anonymous credentials
Prerequisite knowledge
In the following, let elliptic curve with prime order $q$ to be $\mathbb{G}$ and its elements denoted by uppercase letters, and elements on the integer group $\mathbb{Z}_q$ denoted by lowercase.
From Signatures to MACs
As mentioned previously, when a private party uses an anonymous credentials as a service on its own, it can make the assumption that the signer = the verifier.
In such a case, we can assume that the key used for signing and encryption is the same as the key used for verification and decryption. This is symmetric key cryptography.
In symmetric key cryptography, the equivalent of a signature is called MAC (Message Authentication Code)
The MAC commonly used in communication protocols is called HMAC, which is a simple construct based on a cryptographic hash function, but for anonymous credentials, we use the one called Algebraic MAC (AMAC), which uses elliptic point multiplication instead of the hash function.
Using an AMAC instead of a signature in a credential can improve performance by a factor of several to several dozen. (But it will become verifiable only to the issuer.)
Specifically, the calculation is as follows
If the attributes to be authenticated are $m_1$ and $m_2$, then
- Create random values $x_0$, $x_1$ and $x_2$ and use this as secret key. The number of secret key is ("number of attributes" + 1)
- Prepare a point $U$ on an appropriate elliptic curve. This can be a point where no one knows the discrete logarithm (NUMS), or it can be a point where the creator knows the discrete logarithm. In that case, the discrete logarithm should be known only by the creator (i.e. issuer).
- Compute $ T = (x_0 + m_1 * x_1 + m_2 * x_2) * U$ and let ($U$, $T$) be the MAC.
The length of the message must correspond to the $q$, so if the message is too long, it must be seperated to several elements.
Intuitively, it is important to understand that MACs only need to be multiplied once, whereas ordinary attribute-based credentials require a large number of multiplications on an elliptic curve.
Since elliptic curve multiplication is a fairly CPU-heavy computation, this can save a CPU usage considerably.
If we use this construct as an usual MAC, the server can just pass $(U, T)$. And he can verify by re-computing $T$ and check if it maches the one she received. That is, when she got $(U, T)$, checks if the following equation holds
$T = (x_0 + m_1 * x_1 + m_2 * x_2) * U$.
However, in the case of anonymous credentials, this alone is pointless for the following reasons
1.The user who receives the credentials cannot be sure that it is for the intended message.
2. The user who receives the credential cannot verify that it was issued by the appropriate server.
3. The verifier (= issuer) needs to know the value of the message $m_l$.
4. the credential is the same at the time of issuance and presentation, so if the verifier remembers the value he issued, he will know which user is requesting it.
To prevent these problems, we use zero-knowledge proofs.
Zero-knowledge proofs of discrete logarithms
In elliptic curve cryptography, users can convince the verifier that they
- know the discrete log of some elliptic curve point
- those elliptic curve point satisfies some arbitrary linear equations.
without revealing any information besides the statement they want to prove. This is called Zero Knowledge Proof of Knowledge (ZKPoK).
The ZKPoK for simple statements like above, the computation can be done in a fairly efficient manner and its security is well studied.
For example, say the prover computed the values $X_g = x * G$, $X_h = x * H$, and passed those two ($X_g$, $X_h$) to its opponent.
If she wants to prove that the two points are created from the same logarithmic discrete logarithm $x$ (while hiding $x$ itself), first create a random $k$, and calculate the following.
- $R_g = k * G, R_h = k * H$
- $c = Hash(R_g || R_h || X_g || X_h)$
- s = $k + c * x$
And she can pass $(s, c)$ to the verifier.
(I will omit the verification part.)
Since it is tedious to describe such zero-knowledge proofs each time, I will simply write it as follows.
$PK{(x, y): X_g = x * G \land X_h = y * H \land x = y }$
This means "proof of that we know the discrete logarithms for $X_g$ and $X_h$ and that they are identical".
This kind of notation is called Camenisch-Stadler notation.
Keyed Verification Anonymous Credential (KVAC)
This is what is explained as $MAC_{GGM}$ in this paper.
Credential issuance
First, the issuer calculates the MAC in the way I described above. Initially, we will discuss the case where the issuer knows the contents of the message.
For simplicity, we assume that the number of messages is two.
The cretificate itself is just the MAC for the message, i.e. $(U, T)$, but the user needs to verify that it is constructed with private keys which corresponds to issuers public keys, so the issuer will add a zero-knowledge proof to prove that $T = U * (x_0 + m_1 * x_1 + m_2 * x_2)$ holds (while hiding the private keys $x_0$, $x_1$, and $x_2$).
First, the public key of the issuer is calculated and known in advance as follows.
- $C_{x_0} = x_0 * G + r * H$
- $X_1 = x_1 * G$
- $X_2 = x_2 * G$
(The reason why only $x_0$ has a different public key format is because it is more convenient for proving security. For a deeper understanding, see 2.3 at here and original paper.)
Then, add the following zero-knowledge proof at the time of issuance.
$$.
\pi := PK\{ (x_0, x_1, x_2, r) : T = U * (x_0 + m_1 * x_1 + m_2 * x_2 ) \land C_{x_0} = G * x_0 + H * r \land X_1 = x * G \land X_2 = x_2 * G \}
$$.
Addendum: Issue upon LN payment.
I've proposed a scheme where credentials can be purchased by Lightning Network payment at the time of issuance.
This can be viewed from several perspectives, depending on the purpose of the credentials.
-
- prevention of spam requests
- when users anonymously requests credentials, they can DoS the server by requesting a lot of credentials.
- By accepting payments through a private LN channel, the server is completely immune to such attacks.
- There is still the "stop processing just before the user makes a payment" attack vector, in which case the server can just close or ignore the channel.
-
- Atomic Swap
- If the credential encodes a numeric token, such as Stable Coin, this can be considered as an atomic swap of the trustful token for BTC.
-
- Authentication by Payment
- If the credential is used for user authentication, such as Signal, this can be considered as a variant of LSAT.
- Compared to Macaroon based LSATs, there are several Pro/Con.
- Pro
- Anonymity (Multi-show unlinkability)
- The ability to resell rights to others in a trustless manner, (which needs the server to have an endpoint that only performs the verification, since no one else can verify the authenticity.)
- Con
- Computationally intensive
- Non-Interactive restrictive delegation is not possible (i.e. you can't give or sell part of your rights to someone else without communicating with the server).
Note that this mechanism requires Taproot and subsequent LN updates called PTLC.
Hiding attributes from the issuer
So how do we hide an attribute from the issuer?
Lets start from simple (but bogus) way.
Instead of telling the issuer $m$, we can tell him $M = m * G$ without telling him the value of $m$.
In case the $U$ is not NUMS, but some other point $U = b * G$ where the issuer knows the private key $b$, then the credential $(U, T)$ can be calculated from $M$ instead of $m$.
$T = U * (x_0 + x_1 * m_1 + x_2 * m_2) = b * (x_0 * G + x_1 * M_1 + x_2 * M _2)$
This seems OK since server does not know $m$, right?
Unfortunately, No. Since $m$ is not a random value, it is easy for the server to find $m$.
(For example, for age, since $0 < m < 200$, multiplying by $G$ at most 200 times will give a value that matches $M$.)
Normally, in such a case we use a Pedersen Commitments, i.e. generate a random $r$ and then tell the server $m * G + r * H$ to hide the value, but in this case, doing so would make it impossible to calculate the credential.
So instead, we encrypt the attribute we want to hide with ElGamal encryption, pass the ciphertext to the issuer, and decrypt it when the according credential comes back.
This can be done because the ElGamal encryption is a homomorphic encryption.
An ElGamal ciphertext for a message $M = m * G$ is $(r * G, M + r * P)$.
where $r$ is an appropriate blinding factor, and $p, P = p * G$ is the user's private and public key pair.
Decryption is calculated by $c_1 - p * c_2$ when you get ciphertext $(c_1, c_2)$.
Encryption can be done by anyone who knows the public key, but decryption requires the knowledge of the private key $p$.
Since the server does not have the secret key for encryption, it cannot know the value of plaintext $M$ (and thus $m$), but it can calculate the ciphertext of $T$ by utilizing its homomorphic property.
For simplicity, we write $Enc_P(M)$ as "a function that generates an appropriate blinding factor $r$ and creates an ElGamal ciphertext of $M$ from $r$ and the public key $P$.
Homomorphism means that the following equation holds.
$$
Enc_P(A + B) = Enc_P(A) + Enc_P(B)
$$
$$
Enc_P(x * A) = x * Enc_P(A)
$$
The ciphertext of $T$ is
$Enc_P(T) = Enc_P(U * (x_0 + x_1 * m_1 + x_2 * m_2)) = Enc_P(U * x_0) + x_1 * b * (Enc_P(M_1) + Enc_P(M_2))$
From here, we can see that if the server gets $Enc_P(M_1)$ and $Enc_P(M_2)$ from the user, then she can calculate $Enc_P(T)$.
Now, if we return $Enc_P(T)$ to the User, and provide zero-knowledge proof that it was properly created, the User can decrypt it and obtain a valid credential.
At first glance, hiding attributes in this way does not seem to make much sense. (If you issue a credential with age as an attribute, doesn't it make sense not to verify the age?)
In fact, it has the great advantage of "creating a KVAC that reflects the contents of another credential. For example, if a User has an attribute-based credential signed by another municipality, they can have a new credential issued for that service for the same age, with the age hidden.
In this way, it is possible to build an authentication scheme that can be integrated with external schemes without compromising performance.
Credential Presentation
In a primitive PKI-based attribute based credential system, you first give the credential and prove that it contains your private key. But in this case, if you give the credential as it is, the issuer will be able to link the presenter if he remembers the credential when it was issued.
Therefore, we randomize the credential with some secret and prove in zero-knowledge that the value behind the randomized value is a valid credential.
To be little more specific, for example, if you want to prove that you have a credential with $m_1 + m_2 = 1$, you can do the following.
- Let the credential be $(U_0, T_0)$.
- Create a random blinding factor $\alpha, r, z_1, z_2$.
- Send the randomized credential to the verifier.
- $U = \alpha * U_0$
- $T = \alpha * T_0$
- Create a commitment to the message to be proved and send it to the verifier
- $C_{m_1} = U * m_1 + G * z_1$
- $C_{m_2} = U * m_2 + G * z_2$
- $ C_T = G * r + T$.
- Finally, send a zero-knowledge proof that these are properly constructed. $PK{ (\alpha, m_1, m_2, z_1, z_2, r) : U = \alpha * U_0 \land T = T_0 * \alpha \land m_1 + m_2 = 1 \land C_{m_1} = U * m_1 + G * z_1 \land C_{m_2} = U * m_2 + G * z_2 \land V = - G * r + X_1 * z_1 + X_2 * z_2 }$
The verifier can recalculate $V$ without knowing the blinding factors $z_1, z_2$.
$V = U * (x_0 + C_{m_1} * x_1+ C_{m_2} * x_2) - C_T$.
If she can successfully verify the zero-knowledge proof using this $V$, she can tell that the user has a valid credential.
(Basically this is an application of the Diffie-Hellman key exchange to create a shared key. The user and the server create a common value that can only be created by each other, with the user hiding blinding factor and the server hiding the private key respectively, and use it to prove that their credential contains the server's private key without revealing credential itself.)
(Actually when I read this for the first time, I was impressed that authors came up with such a clever mechanism.)
How it is used in a Signal
Modification to KVAC
Signal makes a slight change to the above credential scheme to make the attribute itself an element on $\mathbb{G}$, i.e. a point on an elliptic curve, instead of $\mathbb{Z}_q$.
In a nutshell, this is for the sake of performance, but I'll explain in more detail.
The reason why we want the attribute to be a point on the elliptic curve is because we want to be able to handle the attribute itself in an encrypted form. For example, when an user create a group, she registers her own ID (UID) as a group member in an encrypted form.
However, not just any encryption can be used. It is necessary for a user to prove that a credential exists for the plaintext UID corresponding to the ciphertext. Otherwise, a non-existent user may be registered in the group.
So we want some kind of verifiable encryption scheme.
In this case, if the ciphertext is not an element of $\mathbb{G}$, the existing techniques of elliptic curve cryptography cannot be used, and more complicated cryptographic techniques (such as Paillier cryptography) must be used, which drastically reduces the computational efficiency.
In fact, Signal uses a different mechanism similar to the ElGamal encryption.
The reason for this is that in ElGamal encryption, multiple ciphertexts can exist for a particular plaintext and secret key (because it has a degree of freedom with the blinding factor), which can cause complications such as a same user being registered in the same group more than once, so it uses its own mechanism where the ciphertext and plaintext are one-to-one. (which is not proven CCA-secure by them, BTW.)
For above reasons, credentials used in Signal is more complicated than the one described above, but since the issuance and presentation of the credential is done by concepturally same mechanism, I omit the detailed explanation here.
I do not know how much the performance is affected by this complication, it seems it is more CPU-heavy than $MAC_{GGM}$ based KVAC described above.
Application to group chat
Overview
In general, in a chat application you have three kinds of relation among other users.
- completely unrelated users
- users who can view your profile
- users who belong to the same group chat
Suppose there are two users, Alice and Bob, and Alice wants to register with Bob as a friend so that they can see each other's profiles, and then create a group chat for them.
The flow of the process will be look like this.
- Alice registers her information with the service.
- Alice shares her information with Bob.
- Alice creates a group chat that includes Bob.
- Alice makes a change to the group.
It is important that Alice looks like a different person each time from the server's point of view.
However, the above process should not be done by someone other than Alice. (To be precise, 3 and 4 can be done by Bob, but we will ignore them for simplicity.)
So, at each step, the server gives Alice or Bob certain privileges in the form of anonymous credentials.
Thus they can not link the operation to a specific user.
Create a group
It would be a lot of work to explain the whole process, so I willl just focus on the most important part: Alice registering as a user and creating a group that includes her.
The following diagram summarizes the process.
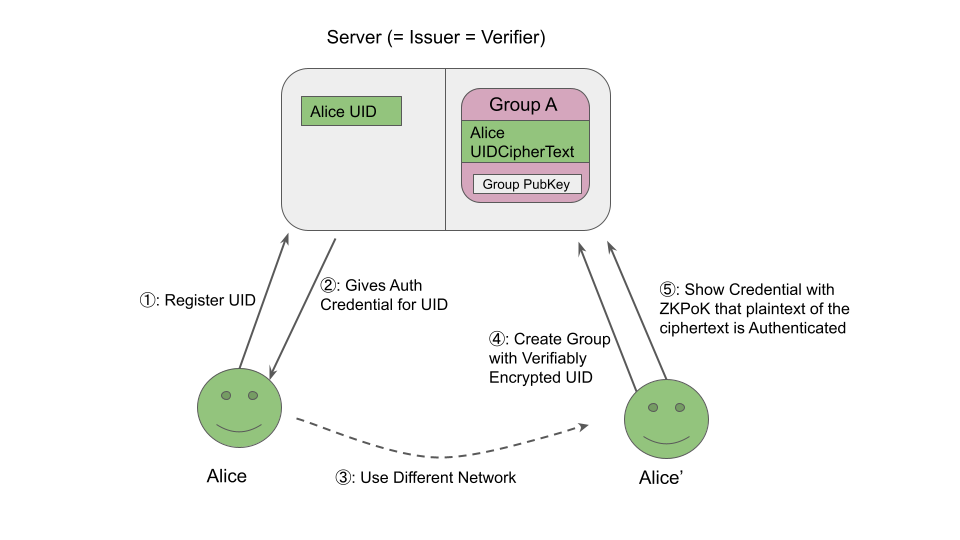
Since the Server needs to know that the encrypted UID belongs to an existing user, Alice provides an anonymous credential to prove it.
Another user in the group can do the same if they know the Group private key, so they can invite other member just by passing the group secret key.
Summary: From "open source" to "open protocol"
The Signal group chat mechanism is an interesting first attempt to apply anonymous credentials to (possibly) commercial services.
The above protocol is too complex to fully understand at first glace.
However the important point is, is that the server has very little risk of the information leakage (except for its own private key).
Existing services will always have to pay security costs to deal with information leakage.
This cost increases as the information being handled gets more sensitive and as the social pressure to ensure proper compliance gets bigger.
The complexity of these protocols makes sense if you think that it is shifting the cost of building "a secure service" to the cost of building "the secure protocol"
And this complexity is publicly verifiable (unlike existing services). In that respect, we can say that the motivation is the same as moving existing financial systems to the public blockchain.
The open source software movement is beginning to see its limitations due to a variety of factors.
Verifiability at the protocol level is in line with this trend in that it does not require the software to be OSS (since anyone can create a client application).
The downside was the difficulty of monetization, but as I mentioned in my previous article, this is something that cryptocurrency can solve.
And just to give you an idea, the mechanism of "the server gives rights to its users according to certain conditions, and the user exercises those rights later." is itself a mechanism that applies to almost all existing web services.
- Netflix ... gives users the right to watch videos based on monthly billing and age verification, and users exercise that right later.
- Twitter ... By presenting ads, it gives users 1. the right to post text, 2. the right to see posts from people they (follow && unblocked), 3. the right to see other users' profiles ... etc.etc. And users exercise them when they need to.
Thus, if we replace the advertising and billing with LN payments, theoretically we can probably build an application with almost the same functionality, but with the anonymity against to the server.
The disadvantages are
- Having recommendation system based on its users information becomes difficult.
- higher computational costs
So certainly it does not replace all existing application.
However, the fact is that anonymity schemes are more valuable in new areas where the advantages outweigh the disadvantages.
For example there is already a one which planning to use it in finance area. It is anonymity-focused bitcoin wallet called Wasabi Wallet.
They are planning to utilize the same mechanism for its CoinJoin coordination protocol.
In general, business domains where anonymity is attractive to users might be those benefit from this kind of scheme. Such as finance, medicine, and public health. At the same time, these are areas where it has been difficult for private corporations to provide such services (due to the protection of personal information).
If you are thinking of providing web services in these areas, Signal's system may be worth considering.
